Pesquise uma videoteca de vários TB localmente, em segundos.
Depois de o seu arquivo estar indexado, o ClipCatalog combina pesquisa por etiquetas, pesquisa de palavras faladas, pesquisa por descrição em linguagem natural, filtros de rostos e filtros de metadados num único caminho de consulta sobre toda a biblioteca. Reduza milhares de clipes a dezenas em poucos cliques.
Sem tarifa por minuto. Sem subscrições. Uma licença única de 99 $ para tornar cada vídeo seu pesquisável em todas as unidades.
O problema do «sei que está aí algures»
Sem pesquisa em toda a biblioteca, só lhe resta percorrer.
Sem pesquisa em toda a biblioteca
- Sabe que o plano existe, mas não em que unidade nem na pasta de que ano
- Os preços dos SaaS na nuvem aumentam com o tamanho da biblioteca — precisamente quando mais precisa de pesquisar
- Ferramentas de função única indexam etiquetas, ou transcrições, ou rostos — mas nunca tudo em conjunto
Com o ClipCatalog
- Uma única barra de pesquisa cobre todas as pastas, todas as unidades e todos os anos de imagens
- Combine uma etiqueta, uma palavra falada, um rosto e um intervalo de datas numa única consulta
- As predefinições guardadas transformam consultas multi-filtro recorrentes em recuperações a um clique
Como funciona a pesquisa em toda a biblioteca de vídeo
À escala dos TB, três condições têm de se verificar: cada clipe tem de estar acessível a partir de uma única pesquisa, cada modo de recuperação tem de correr sobre o mesmo índice, e o índice tem de sobreviver a reorganizações de discos. O ClipCatalog trata das três localmente.
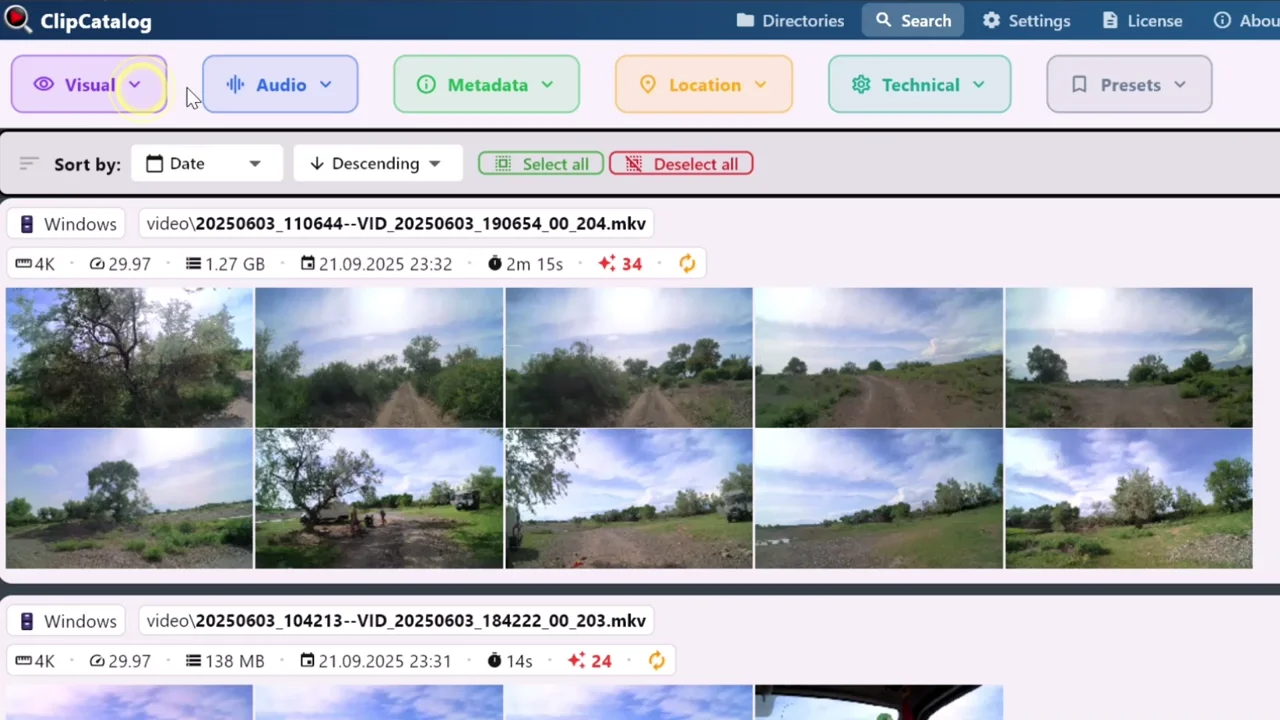
Pesquisa de vídeos →Aponte para cada pasta
Adicione unidades internas, SSD externos, partilhas NAS e discos de arquivo. O ClipCatalog regista cada um por volume de armazenamento, para que o catálogo sobreviva a mudanças de unidade, renomeações e ciclos de desconexão/reconexão. Pode excluir subpastas quando apenas uma parte de um diretório deve ser indexada.
A IA local constrói o índice
A extração de miniaturas, a etiquetagem visual por IA, a transcrição com Whisper, a deteção de rostos e os embeddings para pesquisa em linguagem natural correm todos no seu hardware — DirectML ou Vulkan quando disponíveis, CPU como recurso de reserva. A primeira passagem é um custo único; depois, cada pesquisa bate num índice local.
Pesquise empilhando filtros
Combine numa única consulta filtros por etiqueta, transcrição, rosto, tipo de imagem e metadados. Cada filtro afunila ainda mais o conjunto de resultados — uma biblioteca de 10 000 clips fica reduzida a um punhado em segundos. Qualquer combinação que volte a usar guarda-se como predefinição; a pesquisa seguinte fica a um clique.
Pesquisas em toda a biblioteca que finalmente ficam fáceis
Seis pesquisas que mostram como é, na prática, a pesquisa em toda a biblioteca — de uma única etiqueta visual a uma predefinição guardada que combina quatro filtros ao mesmo tempo. Cada exemplo assume que o índice já está construído; daí em diante, a consulta é a parte fácil.
Quem pesquisa numa videoteca de vários TB?
Seis perfis reais de arquivos em que a pesquisa em toda a biblioteca compensa no momento em que para de rolar e começa a consultar.
Arquivo de televisão noticiosa com conteúdo indexado ao longo de uma década
Cerca de 40 TB, 80 000 clipes, quatro salas de montagem na redação a puxar material todos os dias. Quando rebenta uma história, a pergunta é: «o que já temos sobre esta pessoa, este lugar, este incidente?» Um filtro de rostos + uma pesquisa de uma palavra na transcrição + um intervalo de datas respondem sobre dez anos de cobertura em segundos.
Biblioteca de stock footage com catálogo com direitos libertados ao longo de décadas
Centenas de milhares de clipes, cada um etiquetado pelo que aparece no ecrã. Os compradores chegam com briefings muito específicos («plano aéreo em câmara lenta de uma costa à hora dourada»). Uma pesquisa por descrição em linguagem natural em modo Rigoroso + filtro de tipo cénico + filtro de drone reduz centenas de milhares de clipes a uma lista curta licenciável numa única consulta.
E-discovery legal sobre material de depoimentos e body-cam
Vinte e cinco terabytes de gravações em discovery: depoimentos, extratos de body-cam, capturas de câmaras de bairro. A parte contrária faz uma pergunta; a equipa precisa de todos os clipes em que um termo concreto seja mencionado — rapidamente e sem enviar material sob sigilo a terceiros. Pesquisa de uma palavra na transcrição sobre o conjunto, depois restringir por intervalo de datas e rosto do interveniente.
Análise desportiva sobre bibliotecas multi-época de jogos e treinos
Cinco épocas de captações multicâmara de jogos inteiros mais imagens de treino diário somam dezenas de terabytes. O analista precisa de «todos os contra-ataques iniciados pelo jogador X em jogos que perdemos» — um filtro de rostos + uma pesquisa por etiqueta para a ação + um filtro de metadados para derrotas reduzem anos de gravações a um reel de estudo focado numa só consulta.
Laboratório universitário de média e arquivo de imagem científica ao longo de uma década
Oitenta terabytes de gravações de experiências: ensaios comportamentais, capturas de microscópio, trabalho de campo, rigs de time-lapse. O artigo seguinte precisa de imagens comparáveis de estudos anteriores — uma pesquisa por descrição em linguagem natural em modo Equilibrado mais um filtro de intervalo de datas localiza cada série comparável ao longo da década, sem que um estudante de doutoramento passe duas semanas a escavar discos externos.
Arquivo de pós-produção para projetos de cliente concluídos
Oito anos de projetos concluídos arquivados durante o período de retenção contratual — bem acima dos 100 TB. A produtora volta a pedir «o reel lifestyle da campanha de cosmética da primavera 2024»: uma predefinição guardada que combina etiqueta de cliente + intervalo de datas do projeto + tipo de imagem sem diálogo devolve a bobina certa em segundos, mesmo com a maior parte do arquivo a viver em armazenamento a frio.
O que esperar à escala dos TB
Bibliotecas grandes pressionam todas as etapas de um pipeline de indexação. O ClipCatalog é construído em torno dos compromissos que realmente importam à escala dos TB — aqui está a versão honesta.
O primeiro índice é o maior custo
Planeie a primeira passagem para uma noite ou um fim de semana numa biblioteca com vários TB. Depois de terminada, as sincronizações incrementais só processam os conteúdos novos. Pause e retome conforme necessário — o progresso é preservado.
Os controlos de hardware colocam a velocidade nas suas mãos
Escolha de forma independente o GPU usado para a análise de conteúdo, o GPU usado para a transcrição com Whisper e o dispositivo usado para a deteção de rostos. Execute o benchmark integrado e o ClipCatalog sugere a configuração mais rápida para a sua máquina.
A latência mantém-se viável para além de 100 000 clipes
O índice assenta numa base de dados vetorial local e num catálogo SQLite cifrado afinado para consultas rápidas. Conte com uma consulta por uma etiqueta ou uma palavra a devolver os primeiros resultados em segundos numa biblioteca com 20 000 clipes, e a manter-se responsiva quando a biblioteca duplicar.
Filtros combinados mantêm as listas de resultados manejáveis
Uma biblioteca com 10 000 clipes não tem de lhe dar 10 000 resultados. Empilhe etiquetas, transcrição, rostos, tipo de imagem e metadados — cada filtro afunila ainda mais o conjunto, de modo que o punhado que realmente queria aparece em segundos.
Quatro modos de recuperação, uma biblioteca
A pesquisa por etiquetas usa um vocabulário de IA enumerável; a pesquisa de palavras faladas encontra palavras únicas nas transcrições com Match-All/Match-Any; a pesquisa em linguagem natural ordena os clipes a partir de descrições livres com os níveis Flexível/Equilibrado/Rigoroso; a pesquisa por rostos filtra por pessoas agrupadas a partir dos rostos detetados. Escolha o modo que melhor encaixa na pergunta do momento.
Apenas Windows por agora
O ClipCatalog corre em Windows 10 e 11. A aplicação escolhe o caminho de hardware mais rápido disponível — DirectML, Vulkan ou CPU — mas versões para Mac e Linux não estão no roteiro próximo.
O que «escala TB» significa na prática
Ordens de grandeza concretas em hardware representativo (uma GPU Vulkan recente, disco de catálogo NVMe). Os seus números mudam consoante a mistura de codecs, o tamanho do modelo e a velocidade do armazenamento — encare isto como o enquadramento para planear, não como um SLA fechado.
Biblioteca de teste representativa
≈24 TB de vídeo-fonte, ≈3 000 horas, distribuídos por três unidades internas e uma partilha NAS. Os números abaixo são um modelo de planeamento na ordem de grandeza para uma biblioteca com essa forma — os seus números reais vão variar com o mix de codecs, o hardware e as etapas de IA que ativar.
Latência do primeiro resultado
Uma consulta por uma etiqueta contra o índice completo de 20 000 clipes devolve os primeiros resultados em 2-5 segundos no equipamento de referência. Cada camada extra de filtro acrescenta uma fração de segundo; a parte mais lenta costuma ser o lookup vetorial em linguagem natural.
Espaço ocupado pelo catálogo em disco
Miniaturas, etiquetas de IA, transcrições, dados de rostos e vetores semânticos somam armazenamento ao seu vídeo de origem. O ecrã Definições → Utilização de armazenamento desdobra o total em direto por categoria em MB — meça o seu valor real após o primeiro varrimento de indexação em vez de partir de uma estimativa.
Tempo da primeira passagem de indexação
Para bibliotecas de vários TB, planeie a primeira passagem como trabalho em segundo plano à noite ou ao fim de semana — o tempo de indexação depende muito do mix de codecs, da classe de GPU e do número de etapas de IA ativadas. O pipeline é retomável, pelo que sobrevive a reinícios e a trocas de unidade.
Custo da sincronização incremental
Depois da primeira passagem, só os clipes novos ou alterados voltam a passar pelo pipeline de IA. O índice existente nunca é reconstruído. Uma sincronização diária numa biblioteca em uso costuma chegar a «atualizada» em minutos, mesmo com o arquivo subjacente à escala dos TB.
A economia de pesquisar um arquivo de 10 TB
Os serviços de transcrição na nuvem costumam cobrar entre 0,005 e 0,024 $ por minuto de áudio. Num arquivo de vários TB com centenas de horas de fonte, uma única passagem de transcrição já chega facilmente aos milhares de dólares — e isto antes das tarifas de escalão de armazenamento, dos lugares de pesquisa por utilizador ou do tráfego de saída (a saída na nuvem custa 0,05-0,09 $ por GB, mais 500-900 $ se um dia quiser recuperar 10 TB). A fatura cresce com a biblioteca; quanto mais tempo lá estiver, pior fica a conta.
O ClipCatalog ingere nas unidades que já possui, indexa localmente com o GPU que já tem e guarda tudo numa base SQLite cifrada na sua máquina. 99 $ de pagamento único. Sem custos de largura de banda, sem taxas de saída de dados, sem subscrição. Uma biblioteca de 50 TB e uma de 5 TB custam o mesmo em licença; o custo dominante é o hardware de armazenamento que já possui.
Está a comparar ferramentas local-first para arquivos grandes? Consulte a comparação de gestão de vídeo focada em privacidade para ver como o ClipCatalog se sai em ingestão à escala dos TB, pesquisa em toda a biblioteca e fluxos de trabalho offline.
Pesquisar uma videoteca grande — Perguntas frequentes
Que dimensão de biblioteca consegue o ClipCatalog gerir?
Está concebido para arquivos com vários TB distribuídos por várias pastas, unidades e volumes. A base do catálogo, o índice vetorial e a fila estão pensados para escalar; o teto prático num PC moderno é sobretudo o espaço para miniaturas e embeddings, não uma contagem fixa de vídeos.
Quanto demora a primeira passagem de indexação numa biblioteca de vários TB?
Depende muito do hardware, da mistura de codecs e do número de etapas de IA ativadas. Em vários TB, costuma compensar deixar a primeira passagem a correr durante a noite ou um fim de semana num PC com GPU. A indexação é totalmente retomável.
As consultas mantêm-se rápidas à medida que a biblioteca cresce?
Sim — é justamente o que a arquitetura procura garantir. As pesquisas por etiqueta e transcrição usam colunas indexadas do catálogo SQLite local; as consultas semânticas e de rostos usam um índice vetorial local. Ambas estão pensadas para se manterem rápidas à medida que a biblioteca cresce, pelo que uma biblioteca com 50 000 clipes é apenas marginalmente mais lenta do que uma com 5 000 para a mesma forma de consulta.
Posso guardar combinações de filtros para não as ter de reconstruir?
Sim — as predefinições de pesquisa guardadas são uma funcionalidade de primeira classe. Junte uma pesquisa por etiquetas, um filtro de palavra na transcrição, um filtro de rostos e um intervalo de datas numa predefinição com nome e volte a executá-la com um clique. As predefinições continuam úteis mesmo quando a biblioteca cresce.
Posso mesmo combinar filtros de etiquetas, transcrição, rostos e metadados numa só pesquisa?
Sim. Os filtros das categorias Visual, Áudio, Metadados, Localização e Técnico aplicam-se todos à mesma lista de resultados. Cada um corta as correspondências que não cumprem a sua condição, pelo que filtros em camadas reduzem rapidamente uma lista de cinco dígitos a um número manejável.
As funcionalidades que mais compensam à medida que a biblioteca cresce
Três capacidades pesam de forma desproporcional à escala: as predefinições guardadas que transformam consultas recorrentes num só clique; a classificação por tipo de imagem que separa diálogo, voz off e planos gerais ainda antes de aplicar outros filtros; e uma barra de pesquisa unificada que empilha etiquetas, transcrição, rostos e metadados numa única consulta.
Pesquisa de vídeos
Predefinições guardadas e a interface unificada de pesquisa onde etiquetas, transcrição, rostos e metadados se compõem numa única consulta — a superfície de trabalho onde o filtrar em toda a biblioteca acontece de facto.
Conteúdo detetado
O vocabulário de etiquetas autogerado está pensado para se manter rápido à medida que a biblioteca cresce — a pesquisa por etiquetas numa biblioteca com 100 000 clipes deve sentir-se semelhante a uma com 10 000.
Pesquisa de transcrição
Colunas indexadas no catálogo SQLite local mantêm rápidas as pesquisas de uma palavra na transcrição em centenas de milhares de clipes. O Match-All/Match-Any sobre várias palavras combina-se da mesma forma.
Reconhecimento facial
Os clusters de pessoas sobrevivem ao crescimento da biblioteca: os novos clipes da mesma pessoa juntam-se ao cluster existente, pelo que encontrar tudo com um rosto recorrente continua a ser uma operação a um clique, por maior que a biblioteca fique.
Comparações relevantes
Se estiver a avaliar este fluxo de trabalho em relação a outras ferramentas, comece por estas comparações lado a lado.
Guias relacionados centrados no problema
Encontrar B-roll pelo que aparece em ecrã
Etiquetas visuais autogeradas com combinações Match-All / Match-Any — o complemento natural à pesquisa combinada em toda a biblioteca.
Organize vídeos em discos e NAS
Quando um arquivo passa para a escala dos TB, o material vive quase sempre em vários discos e partilhas NAS. O guia complementar para unificar a camada de armazenamento.
Pesquisar vídeos por palavras faladas
Pesquisa de uma palavra na transcrição num arquivo indexado localmente com Whisper — o complemento palavra a palavra da pesquisa combinada em toda a biblioteca.
Encontrar uma pessoa na sua videoteca
Pesquisa por rosto através de pastas, unidades e anos de imagens — o complemento «por pessoa» da pesquisa combinada em toda a biblioteca.
Experimente o ClipCatalog gratuitamente — até 500 vídeos
Não é necessário criar uma conta. As suas imagens ficam no seu computador.