テラバイト級の動画ライブラリを、ローカルで、数秒で検索。
アーカイブがインデックス化されると、ClipCatalog はタグ検索・発話単語検索・自然言語による記述検索・顔フィルタ・メタデータフィルタを 1 つのクエリ経路に統合し、ライブラリ全体に適用します。数千本のクリップを数クリックで数十本まで絞り込めます。
分単位の課金もサブスクリプションもありません。99 ドルの 1 ライセンスで、所有するすべての動画があらゆるドライブで検索可能になります。
「あの中にあるはず」問題
数テラバイトを超えると、整理されたフォルダ構造だけでは追いつきません。あのカットがある「はず」だとは分かっても、どのドライブの、どの旅フォルダの、どのインタビューの、どのテイクなのかは分かりません。ライブラリ全体での検索がなければ、ひたすらスクロールするしかありません。ClipCatalog なら、問い合わせを投げるだけで、正しいクリップが数秒で出てきます。
ライブラリ全体検索がないと
- あのカットがあるはずだが、どのドライブのどの年フォルダにあるか分からない
- クラウド SaaS の料金はライブラリの規模に比例して膨らみ、検索が最も必要なときほど割高になります
- 単機能ツールはタグ・文字起こし・顔のいずれかしかインデックス化せず、それらを同時にはまとめてくれません
ClipCatalog なら
- 1 つの検索バーで、すべてのフォルダ・すべてのドライブ・すべての年の素材を横断検索できます
- タグ・発話単語・顔・日付範囲を 1 つの検索にまとめられます
- 保存プリセットにより、繰り返し使う複数フィルタ検索がワンクリックで呼び出せるようになります
ライブラリ全体動画検索の仕組み
テラバイト規模では 3 つの条件が満たされている必要があります。どのクリップにも 1 つの検索からアクセスできること、すべての検索モードが同じインデックスを使うこと、そしてドライブの組み替えが起きてもインデックスが生き残ることです。ClipCatalog はこれら 3 つをすべてローカルで処理します。
動画検索 →すべてのフォルダを指定
内蔵ドライブ、外付け SSD、NAS 共有、アーカイブ用ディスクを追加します。ClipCatalog はそれぞれをボリューム単位で追跡するため、ドライブの移動・改名・取り外し/再接続を経てもカタログが生き残ります。一部だけインデックス化したい場合は、サブフォルダを除外できます。
ローカル AI がインデックスを構築
サムネイル抽出、AI による画像タギング、Whisper による文字起こし、顔検出、自然言語検索用の埋め込み生成 — これらすべてがあなたのハードウェア上で動きます。利用可能な場合は DirectML や Vulkan、そうでなければ CPU にフォールバックします。最初のパスはワンタイムコストで、その後の検索はすべてローカルインデックスに対して実行されます。
フィルタを重ねがけして検索
タグ・文字起こし・顔・素材タイプ・メタデータのフィルタを 1 つのクエリに重ねる。フィルタを足すごとに結果が絞り込まれ、1 万本のライブラリが数秒でひと握りに落ちます。よく使う組み合わせは プリセット に保存しておけば、次の検索はワンクリック。
ライブラリ全体検索が、ようやくラクになる例
ライブラリ全体検索が実際にどう動くかを示す 6 つの例。単一のビジュアルタグ 1 つから、フィルタ 4 つを束ねた保存プリセットまで。いずれもインデックスが既に構築されている前提です。そこから先は、検索そのものは難しい部分ではありません。
テラバイト級ライブラリを誰が検索するのか
ライブラリ全体検索の価値が、スクロールから問い合わせへ切り替えた瞬間に分かる 6 つの実際のアーカイブの形。
10 年単位のインデックス済みコンテンツを抱える放送局のニュースアーカイブ
約 40 TB、8 万本のクリップ、編集室 4 室が毎日素材を引き出します。事件が起きたとき、知りたいのは「この人物、この場所、この出来事について何をすでに持っているか」。顔フィルタ + 文字起こし内の単語検索 + 期間指定で、10 年分の取材素材から数秒で答えが出ます。
数十年にわたって権利処理済みのカタログを抱えるストックフッテージライブラリ
数十万本のクリップが、いずれも画面に映っているもの基準でタグ付けされています。買い手は非常に具体的なブリーフを持って来ます(「ゴールデンアワーの海岸線をスローモーションで撮ったドローン映像」)。Strict 設定の自然言語記述検索 + 風景フッテージタイプフィルタ + ドローン フィルタで、数十万本がライセンス可能なショートリストへと一気に絞り込まれます。
証言・ボディカム映像を横断する法的 e-discovery
ディスカバリで扱う 25 TB の記録 — 証言、ボディカム抜粋、近隣カメラのダンプ。相手方弁護士が質問してきたとき、特定の用語が出てくる全クリップを、第三者に封緘資料をアップロードせずに、すぐ揃える必要があります。全体に対する文字起こし内の単語検索を走らせ、日付範囲と話者の顔でさらに絞り込みます。
複数シーズンにわたる試合・練習映像ライブラリ上のスポーツアナリティクス
5 シーズン分のマルチカメラの全試合キャプチャと毎日の練習映像で、合計は数十テラバイト。アナリストが求めるのは「我々が敗れた試合で、選手 X が起点になったカウンター全部」。顔フィルタ + そのプレーのタグ検索 + 敗戦のメタデータフィルタで、年単位のテープが 1 回の検索で集中分析用リールにまとまります。
10 年規模の大学メディア研究室と科学映像アーカイブ
実験記録 80 TB — 行動実験、顕微鏡映像、フィールドワーク、タイムラプス装置。次の論文には過去の研究と比較できる映像が必要です。Balanced 厳密度の自然言語記述検索と期間指定を組み合わせれば、10 年分の中から比較可能な試行をすべて引き出せます。大学院生が 2 週間も外付けドライブを掘り返さずに済みます。
完了したクライアント案件を保管するポストプロダクションのアーカイブ保管庫
契約上の保管期間にわたってアーカイブされた、8 年分の完了プロジェクト — 合計はゆうに 100 TB を超えます。プロデューサーが「2024 年春のコスメキャンペーンのライフスタイル系リール」を再依頼してきたら、クライアントタグ + プロジェクトの期間指定 + 会話のないフッテージタイプを束ねた保存プリセットが、コールドドライブに眠っていても数秒で正しいリールを返してくれます。
テラバイト規模で見込めること
大規模ライブラリはインデックス処理のあらゆる段階に負荷をかけます。ClipCatalog はテラバイト規模で本当に効くトレードオフを軸に設計されています。以下が正直な実情です。
最初のインデックス処理が最大のコスト
数 TB 規模のライブラリでは、最初のパスを一晩や週末に走らせる前提で計画してください。完了後の増分同期では、新規分だけが処理されます。必要に応じて一時停止・再開ができ、進捗は保持されます。
ハードウェア設定で速度を自分でコントロール
コンテンツ解析用の GPU、Whisper 文字起こし用の GPU、顔検出用のデバイスをそれぞれ別々に選べます。内蔵ベンチマークを走らせると、あなたのマシンに最速の構成を ClipCatalog が提案します。
10 万本を超えても検索レスポンスは実用域
インデックスはローカルのベクトル DB と高速検索向けにチューニングされた暗号化 SQLite カタログの上に成り立っています。2 万本のクリップを持つライブラリで、単一タグや単一語の検索は数秒で最初の結果を返し、ライブラリが 2 倍になっても応答性は保たれます。
複合フィルタで結果リストを扱える数に
1 万本のクリップを抱えるライブラリでも、結果が 1 万件出る必要はありません。タグ・文字起こし・顔・フッテージタイプ・メタデータのフィルタを重ねれば、フィルタを足すたびに集合が絞り込まれ、本当に欲しかったひと握りが数秒で浮かび上がります。
4 つの検索モード、1 つのライブラリ
タグ検索は列挙可能な AI 語彙を、発話単語検索は文字起こし内の単一単語を Match-All/Match-Any で扱い、自然言語検索は自由記述に対して Relaxed/Balanced/Strict の厳密度でクリップをランク付けし、顔検索は検出された顔からクラスタリングされた人物で絞り込みます。問いに合うモードを選んで使ってください。
現時点では Windows のみ
ClipCatalog は Windows 10/11 で動作します。利用可能な最速のハードウェア経路 — DirectML、Vulkan、または CPU — を自動で選びますが、Mac/Linux 版は近い将来の予定にはありません。
「テラバイト規模」とは具体的にどういうことか
代表的なハードウェア(比較的新しい Vulkan 対応 GPU、カタログ用に NVMe ストレージ)で見たオーダー感の数字です。コーデックの混在、モデルサイズ、ストレージ速度によって変動するので、計画の目安として読み、厳密な SLA とは見ないでください。
代表的なテストライブラリ
ソース動画 ≈24 TB、合計 ≈3 000 時間。内蔵ドライブ 3 台と NAS 共有 1 つに分散しています。以下の数値はこの形状のライブラリに対するオーダーオブマグニチュード(桁感)の計画モデルで、実際の値はコーデックの構成・ハードウェア・有効にした AI ステージによって変動します。
最初の結果が返るまでの遅延
2 万本のフル インデックスに対するタグ 1 つのクエリは、リファレンス機で 2-5 秒で最初の結果を返します。フィルタを 1 段重ねるごとに 1 秒以下が加算され、最も遅いのはたいてい自然言語ベクトル検索です。
カタログのディスク使用量
サムネイル、AI タグ、文字起こし、顔データ、セマンティックベクトルはいずれもソース動画に加えてストレージを使います。設定 → ストレージ使用量 画面では、現在の合計がカテゴリ別に MB 単位で表示されるので、見積もりではなく初回インデックス後の実測値で計画してください。
最初のインデックス処理に要する時間
数 TB 規模のライブラリでは、初回の取り込みは夜間や週末のバックグラウンド作業として計画してください — 所要時間はコーデックの組み合わせ、GPU のクラス、有効にした AI ステージの数に大きく左右されます。パイプラインは再開可能で、再起動やドライブ交換にも耐えます。
増分同期のコスト
最初のパスが終われば、AI パイプラインを通るのは新規または変更されたクリップだけです。既存のインデックスは再構築されません。稼働中のライブラリの日次同期は、たいてい数分で「最新」に追いつきます。元になるアーカイブがテラバイト規模でも同じです。
10 TB アーカイブの検索コスト
クラウド文字起こしサービスは多くの場合、音声 1 分あたり 0.005-0.024 ドル前後で課金します。数 TB 規模のアーカイブはソース換算で何百時間にもなり、文字起こしを一度回すだけで請求は四桁ドルにまで膨らみます。これにストレージ階層の費用、ユーザー単位の検索シート利用料、データ転送料(クラウドのアウトバウンド転送は GB あたり 0.05-0.09 ドル、10 TB を取り戻したいなら 500-900 ドル追加)はまだ含まれていません。請求はライブラリと一緒に伸び、長く居座るほど数字は悪化します。
ClipCatalog はお手元のドライブからデータを取り込み、既存の GPU でローカルにインデックスを構築し、すべてをマシン上の暗号化された SQLite データベースに格納します。99 ドルの買い切り。帯域も、egress も、サブスクリプションもなし。50 TB のライブラリも 5 TB のライブラリも、ライセンス費用は同じです。支配的なコストは既に持っているストレージ機材の方です。
大規模アーカイブ向けのローカルファースト製品を比較中ですか? プライバシー重視の動画管理ツール比較 で、テラバイト規模の取り込み、ライブラリ全体検索、オフラインワークフローにおける ClipCatalog の位置づけを確認できます。
大規模動画ライブラリの検索 — FAQ
ClipCatalog はどれくらいの規模のライブラリを扱えますか?
数 TB 規模のアーカイブが複数のフォルダ・ドライブ・ボリュームにまたがる構成を想定して設計されています。カタログ DB、ベクトルインデックス、ジョブキューはスケールするように作られており、現代的な PC での実質的な上限は、動画本数というよりサムネイルや埋め込みのためのストレージ容量です。
テラバイト規模のライブラリでは最初のインデックス処理にどれくらいかかりますか?
ハードウェア、コーデックの組み合わせ、有効にする AI ステージの数によって大きく変わります。数 TB 規模のライブラリでは、GPU 搭載 PC で初回パスを夜間や週末にかけて回すのが一般的におすすめです。インデックス処理は完全に再開可能です。
ライブラリが大きくなっても検索は速いままですか?
はい — まさにその点を念頭にアーキテクチャを設計しています。タグや文字起こしの検索はローカルの SQLite カタログのインデックス付き列を使い、意味検索や顔検索はローカルのベクトルインデックスを使います。どちらもライブラリが成長しても速度を保つように設計しているので、同じ形の検索なら 50 000 本のライブラリは 5 000 本のライブラリよりごくわずかに遅いだけです。
毎回作り直さなくて済むようフィルタの組み合わせを保存できますか?
はい — 検索プリセットの保存は主要機能です。タグ検索・文字起こし内の単語フィルタ・顔フィルタ・期間指定を 1 つの名前付きプリセットにまとめ、次回からワンクリックで再実行できます。ライブラリが時間とともに大きくなってもプリセットは有効なまま使えます。
本当にタグ・文字起こし・顔・メタデータのフィルタを 1 つの検索にまとめられますか?
はい。Visual・Audio・Metadata・Location・Technical の各カテゴリのフィルタは、すべて同じ結果リストに適用されます。各フィルタはその条件を満たさないマッチを削っていくので、フィルタを重ねるだけで 5 桁の件数を扱える数まですばやく絞り込めます。
ライブラリが大きくなるほど効いてくる機能
規模が大きくなるほど効果が大きく現れる機能が 3 つあります。繰り返しの検索をワンクリック化する保存プリセット、他のフィルタを適用する前段階で会話・ナレーション・風景を切り分けてくれるフッテージタイプ分類、そしてタグ・文字起こし・顔・メタデータを 1 つのクエリに重ねる統合検索バーです。
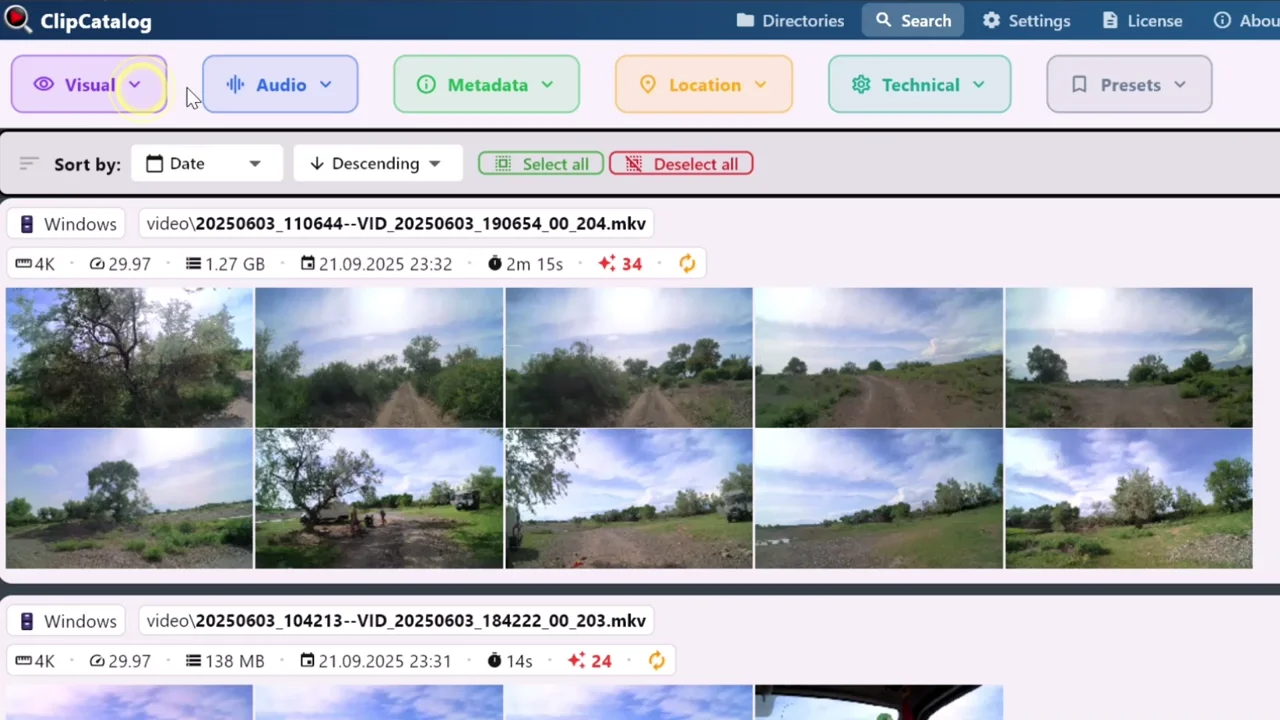
動画検索
保存プリセットと、タグ・文字起こし・顔・メタデータのフィルタが 1 つのクエリにまとまる統合検索インターフェース — ライブラリ全体のフィルタ操作が実際に行われる作業面そのものです。
検出されたコンテンツ
自動生成されるタグ語彙は、ライブラリが成長しても速度を保つように設計しています — 10 万本のライブラリでのタグ検索体験は、1 万本のときと変わらないはずです。
文字起こし検索
ローカル SQLite カタログのインデックス付き列により、数十万本のクリップを横断する単一語の文字起こし検索も高速のままです。複数語の Match-All/Match-Any も同じ仕組みで合成できます。
顔認識
人物クラスタはライブラリの成長に耐えます。同じ人物の新しいクリップは既存のクラスタに紐づくため、繰り返し登場する顔のすべてのクリップを探す操作は、ライブラリがどれだけ大きくなっても 1 クリックのままです。
関連する比較
このワークフローを他のツールと比較している場合は、まずこれらの比較ページをご覧ください。
関連する課題別ガイド
画面に映っているものから B ロールを探す
自動生成された視覚タグと Match-All / Match-Any の組み合わせ — ライブラリ全体での複合検索を自然に補完します。
ドライブと NAS にまたがる素材を整理
アーカイブが TB 規模に達すると、素材はほぼ必ず複数のドライブと NAS 共有にまたがります。ストレージ層を統合するための併読ガイドです。
発話された言葉で動画を検索
ローカルで Whisper によりインデックス化されたアーカイブを対象とする、単語単位の文字起こし検索 — ライブラリ全体の組み合わせ検索を、単語の精度で補完します。
ライブラリ内の人物を見つける
フォルダ・ドライブ・数年分の素材を横断する顔検索 — ライブラリ全体の組み合わせ検索を「人物単位」で補う相棒です。
ClipCatalogを無料でお試しください — 500本までの動画が視聴可能
アカウント不要。撮影した映像はあなたのコンピューターに保存されます。