動画内の話し言葉を検索
ClipCatalog は、動画内の音声を Windows PC 上で検索可能なテキストに変換します。文字起こしやキャプションを検索し、目的の引用や名前を見つけて、その発言があった瞬間へすぐにジャンプできます。
手順を追って確認したいですか? 話された言葉で動画を検索する方法のガイドをご覧ください →
タイムラインをスクラブせずに、ライブラリ全体から名前、話題、印象的なフレーズを検索できます。何時間もの素材を見返す代わりに、必要な一言を数秒で引き出せます。
検索結果は、一致したクリップと発話の瞬間へ直接案内します。プレビューで確認し、そのまま編集へ進めます。
文字起こしはプレーンテキストまたは SRT 字幕ファイルとして書き出せます。編集ソフトで使ったり、キャプションとして公開したり、後で取り出せるよう映像と一緒に保管したりできます。
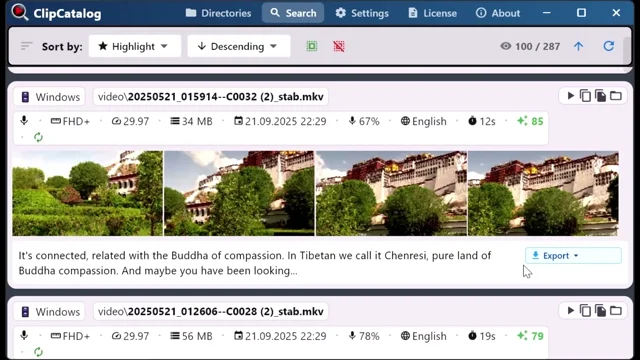
プレーンテキスト、SRT字幕としてエクスポート、またはクリップボードにコピー。
検索可能な文字起こしの仕組み
ClipCatalog は各動画から音声を抽出し、ローカルの Whisper 音声認識エンジンで処理したうえで、時間同期された文字起こし語を暗号化ライブラリに保存します。その後は、アーカイブ全体で話し言葉を検索できるようになります。
任意の動画フォルダを追加してください — 内蔵ドライブ、外付けSSD、またはプロジェクトダンプ。ClipCatalogが自動的にスキャンし、すべての対応動画ファイルを検出します。
ClipCatalog はオーディオを抽出し、ローカルマシン上で Whisper 文字起こしを実行します。ハードウェアが対応している場合、Vulkan による GPU アクセラレーションが利用可能です。対応していない場合は自動的に CPU にフォールバックします。
単語、話題、名前を入力すると、ClipCatalog が一致するクリップを表示します。文字起こし語を検出コンテンツ、人物フィルター、日付範囲などと組み合わせて、必要なものへ正確に絞り込めます。
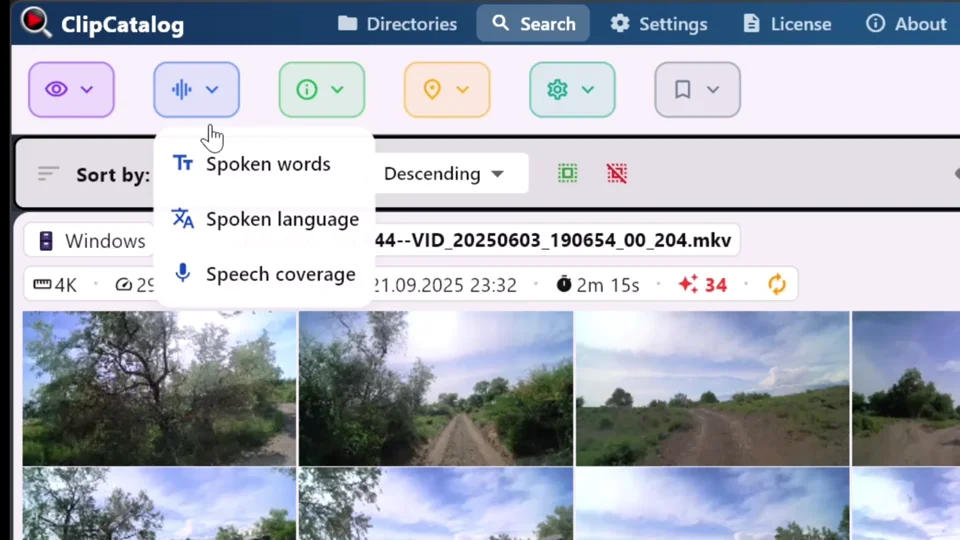
文字起こしフィルター — 単語、言語、音声カバレッジ
ClipCatalogは、単純なキーワード検索を超える、3つのトランスクリプト対応フィルターを提供します:
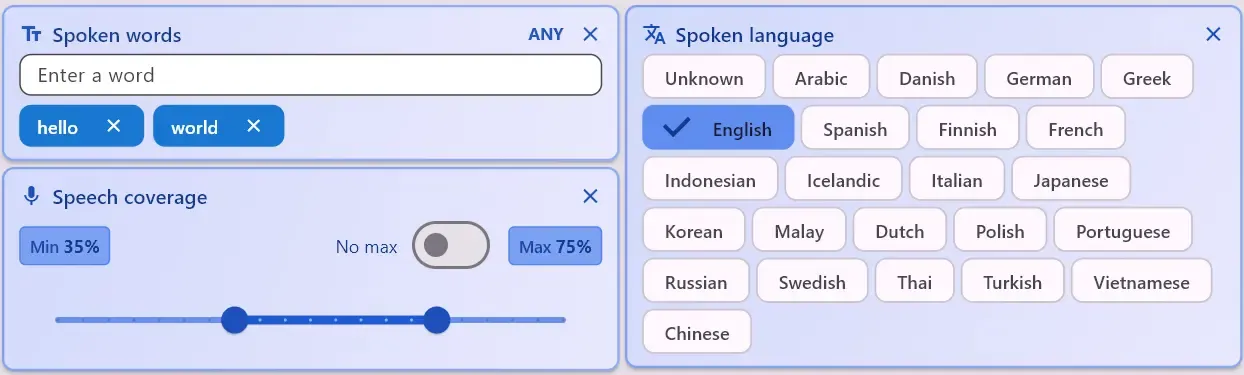
1つまたは複数の発話語を検索できます。複数のトランスクリプト語を入力した場合、すべて(すべての語が含まれる)といずれか(少なくとも1つの語が含まれる)を切り替えて、幅広くまたは絞り込んで検索できます。
検出された言語でフィルタリング — ライブラリに複数の言語の映像が含まれており、特定の言語のみに絞り込みたい場合に便利です。
最小/最大の音声比率を設定し、「主に会話」クリップ(インタビュー、ナレーション)または「主に無音」クリップ(環境音、風景のBロール)を検出します。
文字起こし検索の例
文字起こし検索は、印象的な一言や名前、話題は覚えているのに、どのファイルに入っているか分からないときに特に力を発揮します。自動動画タグ付けと組み合わせれば、視覚的な内容でも同時に絞り込めます。以下は、クリエイターが実際によく行う音声検索(発話検索)の例です。
文字起こし検索は他のフィルターと組み合わせられます。例えば、単語を検索した後、特定の期間、特定のフォルダー、または特定の人物の顔が映っているクリップに絞り込むことができます。すべての検索フィルターを確認する →
動画編集者のための文字起こし検索ワークフロー
複数の撮影日にわたる20時間のインタビュー映像があります。全てを再視聴する代わりに、必要なトピックやキーワード(幼少期、最初の仕事、転機など)を検索し、ストーリー構成に重要な場面に直接ジャンプしましょう。
クライアントが LinkedIn 向けに、CEO がローンチについて話す短いクリップを求めています。長いトーク全体をスクラブする代わりに、重要な話し言葉を検索し、候補をプレビューして、そのまま最適な一言を抜き出せます。
2時間のストリーミングを録画し、クリップに最適な瞬間を見つけたい場合。キーワードや記憶に残る反応を検索し、一致する箇所をプレビューしてクリップをエクスポートできます。録画全体を手動でスクラブする必要はありません。
アクセシビリティやプラットフォーム要件のためにSRTファイルが必要ですか? ClipCatalogはインデックス作成の一環として文字起こしを行うため、字幕ファイルを直接エクスポートできます。別途文字起こし作業やサードパーティサービスは不要です。
自動素材タイプ分類
ClipCatalogが音声処理、コンテンツ検出、顔検出を完了すると、各動画を自動的に以下の素材タイプに分類します: 会話、ナレーション、風景。
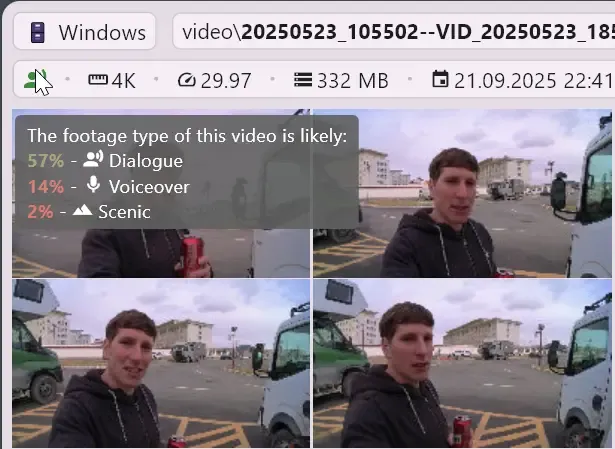
カメラに向かって話す人々の映像——インタビュー、トークヘッド、会話。インタビューの抜粋やAロールを見つけるのに最適。
話者が映っていない音声——ナレーション、Bロール映像への解説、チュートリアル音声。ナレーショントラックを映像コンテンツから分離するのに有用。
音声がほとんどない、あるいは全くない映像素材——風景、Bロール、設定ショット、環境音クリップ。対話のない映像が必要な際に、これらの素材をフィルタリングしてください。
素材タイプの共有数でフィルタリングや並べ替えを行い、編集に最適なクリップを素早く見つけることができます。これは文字起こし検索と併用可能です。例えば、単語を検索し、対話のみのクリップにフィルタリングできます。すべての検索フィルターを閲覧 →
文字起こし検索で期待できること
文字起こしは、インタビュー、ナレーション、ボイスオーバー、会議、講義のような、明瞭で録音状態の良い音声で最も効果を発揮します。こうした素材こそ、特定の一言をすばやく見つける価値が最も高い場面です。
大きな背景騒音、複数の話者の重なり、強い訛りは精度を低下させます。ClipCatalogには品質管理機能が組み込まれており、信頼度の低い文字起こしを抑制するため、検索結果がゴミデータで埋まることはありません。
Windowsでは、文字起こし処理がVulkan経由でGPUを利用し、処理を高速化できます。ClipCatalogにはハードウェア上でCPUとGPUの速度を比較する組み込みベンチマークが搭載されており、最適なバックエンドを自動選択します。 GPUの高速化について詳しく知る →
音声データは一切外部に送信されません。Whisperエンジンは完全にローカルで動作するため、機密性の高いインタビュー内容、クライアントの映像、個人録音は完全に非公開です。ローカルファーストのプライバシーについて詳しくはこちら →
よくある質問
ClipCatalog は Windows 上の大規模なローカル動画ライブラリ向けに作られています。フォルダ、外付けドライブ、アーカイブボリュームにわたるすべての発話をインデックス化し、引用・話者・キーワードでの検索を顔・シーン・メタデータのフィルターと組み合わせられます — すべて 100% オフライン、分単位の課金もありません。
はい — ClipCatalog は、文字起こしベースの動画検索ができる Windows 向けデスクトップアプリです。フォルダをドロップすればローカルで音声がインデックス化され、ライブラリ全体の文字起こしを検索できます。クラウドへのアップロードもサブスクリプションも不要で、無料トライアルは無期限です — 任意で一度だけ 14 日間のライブラリ全体拡張も利用できます。
はい。ClipCatalogは初回のインデックス作成時にライブラリ内のすべての動画に対して検索可能な字幕を生成し、ローカルに保存して、再処理せずにコレクション全体を検索できるようにします。字幕はSRT形式でエクスポートできます。
いいえ — ClipCatalog は音声認識を完全にローカルの Whisper エンジンを使用して、お使いのコンピューター上で実行します。音声ファイルや動画ファイルがクラウドサービスにアップロードされることは一切ありません。
まだです。ClipCatalog は文字起こしされた単語(単一の話し言葉)を検索対象とし、正確なフレーズや順序付き引用は対象外です。
ClipCatalogは、評価の高い音声認識モデル「Whisper」を採用しています。対応言語における明瞭な発話では概ね高い精度を発揮しますが、強いアクセント、背景雑音、複数の話者が同時に話す状況では精度が低下する場合があります。アプリには信頼度の低い結果を抑制する品質管理機能が組み込まれています。
Whisperは多くの言語に対応しています。ClipCatalogが話された言語を自動検出するため、文字起こし言語でライブラリをフィルタリングできます。アプリのUIと検出されたコンテンツは10言語に対応しています。
はい — 文字起こしはプレーンテキストまたはSRT字幕ファイルとしてエクスポートでき、編集ソフトでの使用やYouTubeなどのプラットフォームでの字幕公開にすぐ利用できます。
AIモデルは初回起動時にダウンロードされ、その後はインターネット接続なしで文字起こしと検索がローカルで実行されます。ライセンス認証には時折インターネット接続が必要です。
文字起こし処理は検索のたびに実行されるのではなく、一度限りの処理ステップ中に実行されます。インデックス作成後は検索が瞬時に感じられます。高性能なGPUをお持ちの場合、Vulkanによる高速化された文字起こし処理により処理速度が向上します。
はい。文字起こしされた単語に、検出されたコンテンツ、顔フィルター、日付範囲、フォルダー、カメラのメタデータなどを重ねて表示できます。これらすべてを単一のクエリで実行可能です。各フィルターは結果をさらに絞り込みます。
大規模な動画ライブラリ全体で文字起こし検索を組み合わせる
文字起こし検索は単独でも強力ですが、真の強みはClipCatalog内の他の検索次元と組み合わせることで、数千のクリップから必要な瞬間を正確に見つけ出せる点にあります。単語、タグ、顔認識を横断し、すべて一致/いずれか一致(AND/OR)を切り替えられます。
発言内容と画面上の情報を組み合わせる——対話とシーン内容を同時に検索する。
人物フィルターと文字起こし検索を組み合わせて、特定の人物が特定の話題について話しているクリップを見つけられます。
アーカイブドライブ全体で記録を検索する — 現在接続されていないドライブも対象とする。
日付、フォルダ、解像度、フレームレート、音声カバー率などを含めた文字起こしデータをレイヤー化します。
人物検索のタスク別ガイドが必要ですか? 1本のクリップを再利用できる顔フィルターに変える流れをここから確認できます。
関連する比較
このワークフローを他のツールと比較している場合は、まずこれらの比較ページをご覧ください。
最適
- ドキュメンタリー映画製作者が、何時間にも及ぶインタビュー映像から引用文を抽出している。
- YouTubeクリエイターやVlogger 長編録画からハイライトを切り出したい方。
- ポッドキャスト編集者がエピソード全体で特定のトピックを検索する。
- 企業動画チームがソーシャルメディアや社内コミュニケーション向けに短い引用文を探す。
1つのフォルダで試してみてください
文字起こし検索を試す最適な方法は、インタビュー、ポッドキャスト、会議、または会話量の多い素材が入ったフォルダを選び、ClipCatalog で処理したあと、誰かが話した具体的な内容を 3 から 5 個見つけてみることです。
動画の文字起こし検索の理解
音声テキスト検索、対話検索、キャプション検索、あるいは「動画版 Ctrl+F」と呼んでも、本質は同じです。ソフトウェアが話し言葉をテキストに変換し、ファイル名やフォルダ構成ではなく、実際に話された内容で映像を探せるようにします。
クラウド文字起こしサービスは音声1分あたり課金されます。ClipCatalogでは、Whisperモデルが自社ハードウェア上で動作するため、動画ごとの費用・アップロード待ち時間・継続的なサブスクリプションは不要です。 処理速度はご利用のマシンに依存します:高性能なGPUなら高速ですが、CPUのみの場合は大規模ライブラリで遅くなります。いずれにせよ、費用は初期設定時のみです。アーカイブがインデックス化されれば、検索は瞬時に行われ、その後は一切費用がかかりません。
編集者は撮影時の言葉や話題を覚えていても、どのファイルにあるか分からないことがよくあります。文字起こし検索機能がない場合、クリップを一つずつ手動で確認するか、インタビュー全体を再視聴するしかありません。検索可能な文字起こしがあれば、覚えている言葉を入力するだけで該当クリップが数秒で表示され、手作業による確認作業を何時間も短縮できます。
単一の単語検索では数十のクリップが返される可能性があります。ClipCatalogのトランスクリプト検索の真価は、他のフィルターと組み合わせることです。「予算」を検索し、特定の日付範囲、特定のフォルダー、またはAIビジュアルタグ付けツールで「インタビュー」タグが付けられたクリップに絞り込みます。追加するフィルターごとに結果が絞り込まれるため、誤検出をいちいち確認する必要がありません。 すべての検索フィルターを見る →
ClipCatalogは、各クリップ内の音声含有量(スピーチカバレッジ)を追跡します。これにより、「主に会話が収録されたクリップを表示」(インタビュー用クリップ)や「音声がほとんどないクリップを表示」(風景用Bロール)といった操作が可能になります。会話中心の映像素材と、環境音や音楽主体のコンテンツを分離する上で、驚くほど有用な手法です。
ClipCatalogを無料でお試しください — 500本までの動画が視聴可能
アカウント不要。撮影した映像はあなたのコンピューターに保存されます。