AIによる自動動画タグ付けソフトウェア — 検出されたコンテンツで映像を検索
ClipCatalogは自動動画タグ付けツールとして、あなたのクリップをチェックしてシーン・物体・動作を検出します — 手動でのラベル付けやクラウドへのアップロードは不要です。思い出すキーワードを入力するだけで、一致するクリップが即座に表示されます。複数のタグを組み合わせる場合、すべて一致(AND)またはいずれか一致(OR)を切り替えられます。
ClipCatalogでは、AIが自動生成する動画タグを検出されたコンテンツと呼びます。AIが各クリップを分析し、映っている内容に基づいてタグを付与するため、ファイルを手動でラベル付けすることなく映像を見つけられます。
ステップごとの手順をお探しですか?画面に映っているものから B ロールを探す方法 をご覧ください →
命名規則やフォルダ構造を独自に作成するのはやめましょう。検出されたコンテンツは処理中に自動生成されます。検索は行いますが、並べ替えは行いません。
「山」や「インタビュー」を思い出したら、そのまま入力してください。ClipCatalogが検索結果を素早く絞り込むので、クリップをくまなく探す時間を短縮できます。
動画ファイルは巨大で個人的なものです。ClipCatalogはすべてをローカルで処理するため、撮影素材がクラウドサービスにアップロードされて検索可能になることはありません。
検出されたコンテンツの仕組み
ClipCatalogのオンデバイスAIモデル(RAM++)は、クリップのフレームを分析し、ビーチ、車、インタビュー、雪、犬、都市のスカイラインなどのコンテンツラベルを検出します。 これはクリップのスマートな目次のようなものと考えてください。「このクリップの内容は?」「このクリップにXは含まれているか?」といった疑問に最適です。
任意の動画フォルダを追加 — 内蔵ドライブ、外付けSSD、プロジェクトのダンプファイルも可。再編成は不要です。
ClipCatalogはクリップをインデックス化し、GPU(自動CPUフォールバック付き)を使用してコンテンツを検出します。何も端末外に送信されません。
覚えていることを入力すると、一致するクリップが表示されます。検出されたコンテンツを他のフィルターと組み合わせれば、数千のクリップから数個に絞り込めます。
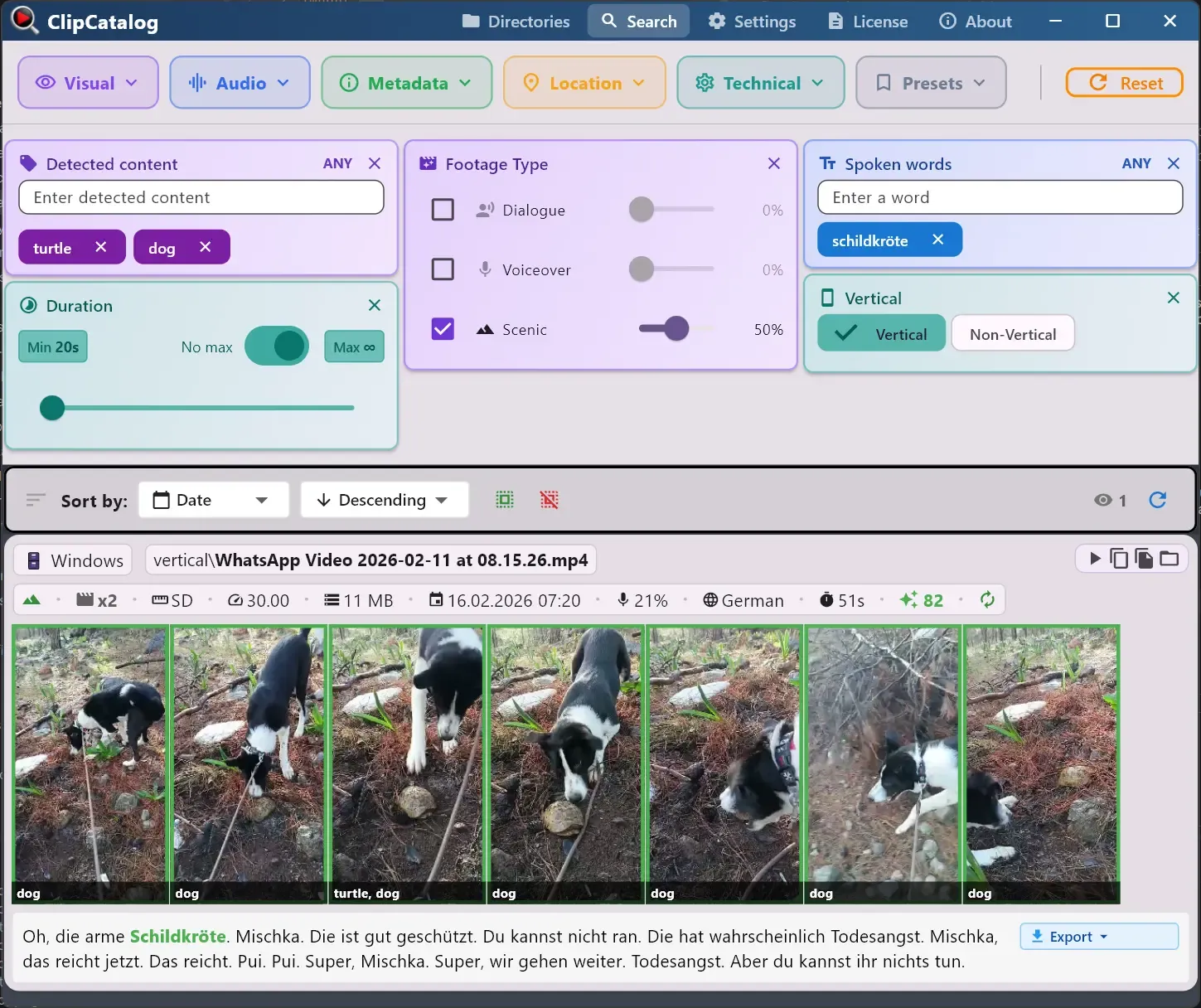
効果的な検索の種類
「数千の検出可能なラベル」と主張する代わりに、以下はクリエイターが実際に実行し、結果を得ている現実世界の検索例です:
検索を組み合わせることも可能です。例えば「ビーチ」で検索した後、ショートやリール向けに縦向き動画のみに絞り込んだり、特定の日付範囲やフォルダーでフィルタリングしたりできます。すべての検索フィルターを見る →
実世界のワークフロー
「ドローンビーチの広角ショット」は覚えているが、ファイル名は思い出せない。検出されたコンテンツを活用すれば、自然な検索を数回試すだけで素早く絞り込める——何十ものクリップをスクロールして探す必要はない。
小規模チームはBロールを再利用することが多い。画面上の内容(フォルダ名だけでなく)で検索できると、アーカイブは一度きりのダンプではなく、再利用可能な資産となる。
スマートフォンやカメラ、ハードドライブに蓄積された長年の映像。シーンや人物で検索すれば、誕生日の瞬間や旅行のハイライト、あの思い出のクリップが、フォルダを次々に開かなくても見つかります。
変更前: A-cam、B-roll、 Export_v7_FINAL。変更後: 記憶しているキーワードを入力するだけで検索可能なライブラリ。
ClipCatalogは各クリップに、視覚的な興味度、動き、音声、顔、その他の要素に基づくハイライトスコアを付与します。ハイライト順でソートすれば、最も力強くダイナミックなクリップが最初に表示されます。すべてを視聴せずに大規模ライブラリから際立つ瞬間を見つけたい場合に便利です。
検出されたコンテンツから何が期待できるか
あるものは簡単に見つけられるが、あるものは微妙で、フレーム内で小さく映るか、ほんの一瞬しか現れない。勝因は、素早く「適切な領域」のクリップにたどり着くこと——そして最高のテイクを選ぶことだ。
自動ラベル付けによる無関係な結果のスパムに悩まされた経験があるなら、ClipCatalogは検出されるコンテンツを、検索に有用なものに集中させます。目的は、実際に打ち込む言葉に対して、より少ないノイズとより多くの結果を提供することです。
Windowsでは、ClipCatalogが(DirectMLを経由して)あなたのGPUを利用し、コンテンツ検出を高速化します。GPUのアクセラレーションが利用できない、または効果的でない場合、自動的にCPUにフォールバックします。可能な時は高速に、不可能な時は耐障害性を発揮します。 GPUアクセラレーションについて詳しく知る →
ドライブを再編成しなくてもメリットを享受できます。既存のフォルダ構造はそのまま維持しつつ、ライブラリは検索可能で編集しやすい状態になります。外部ドライブにも対応 →
AIタグ付け vs. 手動タグ付け
大規模な動画ライブラリを検索可能にする2つの方法。それぞれに役割があります — カタログ規模での比較を見てみましょう。
全クリップを視聴し、説明を書き、スプレッドシートを保守し、誰もが従わなければならないフォルダ命名規則を考案します。結果は正確ですが、1クリップあたりの労力は数百クリップを超えるとスケールせず、2人がスプレッドシートを編集した瞬間にラベルがずれ始めます。
ClipCatalogをフォルダに向けるだけで、デバイス上のモデルが処理中にシーン・物体・動作タグを割り当てます。命名規則の厳格さは不要、1クリップあたりの労力もゼロ、そして同じライブラリはモデルが改善された後に — 何も見直すことなく — 再タグ付けできます。
AIタグ付けは、手動ラベル付けが要する時間のごく一部で典型的なライブラリを完了し、目的のクリップ群へ素早く案内するには十分な精度です。手動ラベル付けは、繊細または主観的なカテゴリ — 雰囲気、ナラティブのビート、ブランド固有の用語 — でより正確です。両者は補完的です。AIタグが重労働を担い、本当に重要なケースには手動ラベルを重ねられます。
ローカル AI タグ付けの比較
「最高の動画タグ付けソフト」一覧の多くは、分単位や席単位で課金されるクラウドサービスです。個人やスタジオのライブラリ向けに、オフラインで買い切りのデスクトップアプリがどう比較されるかを示します。
| ローカル AI タグ付けの比較 | ClipCatalog | クラウド動画 AI | 写真・動画 DAM |
|---|---|---|---|
| AI の実行場所 | 自分の PC(GPU または CPU) | サーバーにアップロード | 多くはクラウド、またはなし |
| あなたの映像 | PC の外に出ません | 処理のためアップロード | 製品による |
| 価格 | 99 ドル買い切り | 分単位または月額 | 席単位のサブスク |
| 検出できるもの | シーン・物体・動作——さらに音声と繰り返し登場する顔 | API による | 主に手動キーワード |
| ライブラリの範囲 | 所有するすべてのドライブ・フォルダー・NAS | アップロードした分のみ | 単一カタログ |
| プラットフォーム | Windows デスクトップ | ブラウザー / API | デスクトップ |
クラウドや DAM の機能はベンダーによって異なります。ここでは特定の製品ではなくカテゴリーとして比較しています。
よくある質問
いいえ — 検出されたコンテンツは、ライブラリが処理される間に自動的に生成されます。検索時は、普段通りに入力する言葉を使って検索するだけです。
いいえ。処理はすべてお使いのコンピューター上で行われます。撮影した映像はクラウドサービスにアップロードされることはありません。
アプリが初回起動時にAIモデルをダウンロードすると、コンテンツ検出と検索はインターネット接続なしでローカル上で行われます。ライセンス認証には時々インターネット接続が必要です。
処理中はインデックス作成に多大なCPU/GPUリソースを消費するため、その間はマシンの動作が遅く感じられる場合があります。これは一度限りの作業であり、ライブラリのインデックス作成が完了すれば検索は瞬時に行われます。高性能なGPUは処理を高速化し、必要に応じて処理スレッドの一時停止や制限が可能です。
近い類義語を試してみてください——人によって記憶の仕方は異なります。より広い意味の情景を表す言葉も試せます。真の検索は反復的なもので、完璧なクエリ一つではありません。
はい。検出されたコンテンツに日付範囲、フォルダー、文字起こしテキスト、顔フィルター、技術的なメタデータを重ねて適用することで、大規模なライブラリを素早く絞り込むことができます。
従来のメタデータは技術的な詳細(解像度、コーデック、日付)をカバーします。検出されたコンテンツは、ショットに実際に何が映っているかというコンテンツ層を追加するため、数値だけでなく意味で検索できるようになります。
ClipCatalogはWindows 10/11上で動作します。高性能なGPUはDirectMLを介して処理を高速化しますが、アプリは自動的にCPUにフォールバックします。開始するのに特別なハードウェアは必要ありません。
AI動画タグ付けとは、機械学習を使って映像の内容に基づきクリップに自動でラベルを付けることです。ClipCatalogではこれを検出されたコンテンツと呼びます。AIが各クリップを視聴し、「ビーチ」「インタビュー」「車」などのタグを付与するため、ファイルを手動で整理しなくても検索できます。
検出されたコンテンツとは、AIによる自動動画タグ付けを指すClipCatalogの用語です。フォルダを追加すると、アプリが各クリップを分析し、映っている内容(シーン、物体、動作)を表すタグを付与します。これらのタグで検索・絞り込みができ、トランスクリプトや顔フィルターと組み合わせたり、全一致・いずれか一致モードを切り替えたりできます。
はい — ClipCatalogはWindows 10/11向けの自動動画タグ付けツールです。任意のフォルダに向けるだけで、ローカルGPU(CPUフォールバック付き)でシーン・物体・動作別にクリップにタグを付けます。クラウドへのアップロードは一切なく、最初の500本まで無料でお試しいただけます。
AI動画タグ付けは、手動ラベル付けが要する時間のごく一部で典型的なライブラリを完了し、目的のクリップ群へ素早く案内するには十分な精度です。手動ラベル付けは、繊細または主観的なカテゴリでより正確です。両者は補完的で、AIタグが重労働を担い、本当に重要なケースには手動ラベルを重ねられます。
いいえ。ClipCatalog は「ボトル」「車」「ノートパソコン」といった日常的な物体や視覚的概念にタグを付けて検索できるようにしますが、特定のブランド・ロゴ・製品型番・バーコードは識別しません。製品データベースはなく、検出されたコンテンツは画面に写っているものの種類を表すもので、具体的にどの製品かまでは特定しません。
あります。ClipCatalog は Windows デスクトップアプリの買い切り(99 ドル)で、月額や分単位のクラウドサブスクではありません。無料体験では最初の 500 本にタグを付けられ、クレジットカードもアカウントも不要です。
できます。ClipCatalog は 1 回のローカル処理で複数の検索シグナルを作成します。画面内容の AI タグ、発話内容の検索可能な文字起こし、繰り返し登場する顔のグループ化、映像タイプのフィルター(会話・ナレーション・風景)です。1 回の検索で組み合わせられ、すべて PC 上で行われ、何もアップロードしません。
共に力を合わせれば、さらに強力に
検出されたコンテンツはそれ自体で強力ですが、真の強みはClipCatalog内の他の検索次元と組み合わせることで、数千ものクリップから必要なものだけを正確に絞り込める点にあります。
関連する比較
このワークフローを他のツールと比較している場合は、まずこれらの比較ページをご覧ください。
最適
- YouTubeクリエイターや動画ブロガーが、数十日にわたる撮影素材からBロールを探す場面。
- 映像制作者と編集者がTB規模のプロジェクトアーカイブを扱う。
- 家族と旅行の記録保管者が、長年にわたる個人の映像を整理しています。
- クライアントプロジェクト間で映像素材を再利用する小規模チーム。
- 1 つのクリップではなく、画面に映っているものから B ロールをライブラリ全体から引き出したい編集者の方に。
1つのフォルダで試してみてください
検出されたコンテンツが自分の映像に合うか確認する最良の方法:単一のプロジェクトフォルダまたは単一の撮影日の素材を処理し、検出されたコンテンツのみを使用して「確かにどこかで撮影したはず」という瞬間を5~10箇所探し出してみてください。
ClipCatalogを無料でお試しください — 500本までの動画が視聴可能
アカウント不要。撮影した映像はあなたのコンピューターに保存されます。