Rechercher dans une vidéothèque de plusieurs To, en local, en quelques secondes.
Une fois votre archive indexée, ClipCatalog combine la recherche par tag, la recherche dans les transcriptions, la recherche par description en langage naturel, les filtres de visages et les filtres de métadonnées en un seul chemin de requête sur toute la bibliothèque. Passez de milliers de clips à quelques dizaines en quelques clics.
Aucun tarif à la minute. Aucun abonnement. Une licence unique à 99 $ pour rendre chacune de vos vidéos consultable sur tous vos disques.
Le problème du « je sais que c'est là quelque part »
Au-delà de quelques téraoctets, même une bonne arborescence de dossiers ne suffit plus. Vous savez que le plan existe, mais pas sur quel disque, dans quel dossier de voyage, dans quelle interview, dans quelle prise. Sans recherche couvrant toute la bibliothèque, vous faites défiler. Avec ClipCatalog, vous lancez une requête — et le bon clip apparaît en quelques secondes.
Sans recherche couvrant toute la bibliothèque
- Vous savez que le plan existe, mais pas sur quel disque ni dans quel dossier d'année
- Les SaaS cloud sont facturés en fonction de la taille de la bibliothèque, justement quand on a le plus besoin de chercher
- Les outils monovalents indexent soit les tags, soit les transcriptions, soit les visages — jamais tout en même temps
Avec ClipCatalog
- Une seule barre de recherche couvre tous les dossiers, tous les disques et toutes les années de rushes
- Combinez un tag, un mot prononcé, un visage et une plage de dates dans une même requête
- Les préréglages enregistrés transforment les requêtes multi-filtres récurrentes en rappels d'un clic
Comment fonctionne la recherche couvrant toute la bibliothèque
À l'échelle des téraoctets, trois conditions doivent être réunies : chaque clip doit être accessible depuis une seule recherche, chaque mode de récupération doit utiliser le même index, et l'index doit survivre aux réorganisations de disques. ClipCatalog gère les trois en local.
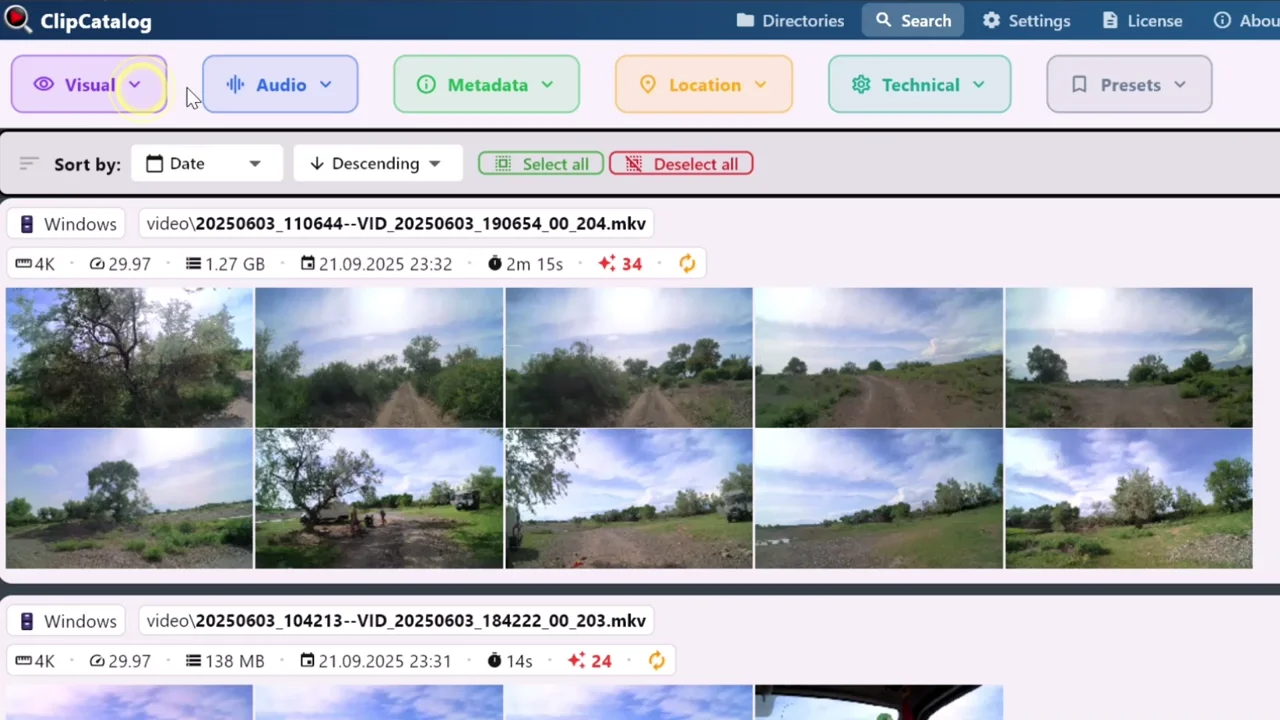
Recherche vidéo →Pointer vers chaque dossier
Ajoutez disques internes, SSD externes, partages NAS et disques d'archive. ClipCatalog suit chacun d'eux par volume de stockage afin que le catalogue survive aux déplacements de disques, aux renommages et aux cycles de débranchement/rebranchement. Vous pouvez exclure des sous-dossiers quand seule une partie d'un répertoire doit être indexée.
L'IA locale construit l'index
Extraction des miniatures, tagging visuel par IA, transcription Whisper, détection de visages et embeddings pour la recherche en langage naturel tournent tous sur votre matériel — DirectML ou Vulkan quand c'est possible, repli CPU sinon. Le premier passage est un coût unique ; ensuite, chaque recherche frappe un index local.
Rechercher en empilant des filtres
Combinez dans une même requête des filtres par tag, transcription, visage, type de prise et métadonnées. Chaque filtre resserre encore la liste de résultats — une bibliothèque de 10 000 clips se réduit à une poignée en quelques secondes. Toute combinaison que vous referez se sauvegarde en préréglage ; la recherche suivante est à un clic.
Des recherches couvrant toute la bibliothèque enfin faciles
Six recherches qui montrent à quoi ressemble en pratique la recherche couvrant toute la bibliothèque — du tag visuel unique au préréglage enregistré combinant quatre filtres à la fois. Chaque exemple suppose que l'index est déjà construit ; ensuite, la requête est la partie facile.
Qui cherche dans une vidéothèque de plusieurs To ?
Six profils d'archives réels où la recherche couvrant toute la bibliothèque rembourse son ticket d'entrée dès que vous arrêtez de faire défiler pour interroger.
Archive d'actualités télévisées avec un fonds indexé sur une décennie
Environ 40 To, 80 000 clips, quatre régies de montage qui tirent du contenu chaque jour. Quand une info tombe, la question est : « qu'avons-nous déjà sur cette personne, ce lieu, cet incident ? » Un filtre de visages + une recherche d'un mot dans la transcription + une plage de dates y répondent sur dix ans de couverture en quelques secondes.
Bibliothèque de stock-footage avec catalogue droits-libérés sur des décennies
Des centaines de milliers de clips, chacun étiqueté selon ce qu'on y voit. Les acheteurs arrivent avec des briefs très précis (« plan aérien au ralenti d'un littoral à l'heure dorée »). Une recherche en langage naturel en mode Strict + filtre de type scenic + filtre drone ramène des centaines de milliers de clips à une présélection licenciable en une seule requête.
E-discovery juridique sur des dépositions et body-cams
25 téraoctets d'enregistrements en discovery : dépositions, extraits de body-cam, extractions de caméras de voisinage. La partie adverse pose une question ; l'équipe doit retrouver chaque clip où un terme précis est prononcé — vite, sans envoyer du matériel sous scellés à un tiers. Recherche d'un mot dans la transcription sur l'ensemble, puis restriction par plage de dates et visage du locuteur.
Analyse sportive sur des bibliothèques multi-saisons de matchs et d'entraînements
Cinq saisons de captations multi-caméras des matchs entiers, plus l'entraînement quotidien, ça fait des dizaines de téraoctets. L'analyste veut « chaque contre-attaque déclenchée par le joueur X dans les matchs perdus » — un filtre de visages + une recherche par tag pour l'action + un filtre de métadonnées pour les défaites ramènent des années de rushes à un montage d'analyse ciblé en une requête.
Laboratoire média universitaire et archive d'imagerie scientifique sur une décennie
Quatre-vingts téraoctets d'enregistrements d'expériences : essais comportementaux, captures de microscope, terrain, montages en time-lapse. Le prochain article exige des séquences comparables tirées d'études plus anciennes — une recherche en langage naturel en mode Balanced plus un filtre de plage de dates fait remonter chaque manip comparable sur dix ans, sans qu'une doctorante doive passer deux semaines à fouiller des disques externes.
Coffre d'archive post-production pour les projets clients terminés
Huit ans de projets terminés archivés pour la durée de rétention contractuelle — bien au-delà de 100 To. La productrice revient demander « le montage lifestyle de la campagne cosmétique du printemps 2024 » : un préréglage enregistré combinant tag client + plage de dates du projet + type de plan sans dialogue ressort le bon montage en quelques secondes, même si l'essentiel de l'archive vit sur des disques de stockage à froid.
À quoi s'attendre à l'échelle des téraoctets
Les grandes bibliothèques mettent sous pression chaque étape du pipeline d'indexation. ClipCatalog est conçu autour des compromis qui comptent vraiment à l'échelle des téraoctets — voici la version honnête.
La première indexation est le coût principal
Sur une bibliothèque de plusieurs To, prévoyez la première passe sur une nuit ou un week-end. Une fois terminée, les synchronisations incrémentales ne traitent que les nouveautés. Mettez en pause et reprenez : la progression est conservée.
Les réglages matériels mettent la vitesse entre vos mains
Choisissez indépendamment le GPU utilisé pour l'analyse de contenu, le GPU utilisé pour la transcription Whisper et l'appareil utilisé pour la détection de visages. Lancez le benchmark intégré et ClipCatalog vous propose la configuration la plus rapide pour votre machine.
La latence reste praticable au-delà de 100 000 clips
L'index s'appuie sur une base de données vectorielle locale et un catalogue SQLite chiffré optimisé pour les recherches rapides. Comptez sur une requête par un tag ou un mot pour renvoyer ses premiers résultats en quelques secondes sur une bibliothèque de 20 000 clips, et rester réactive même quand la bibliothèque double.
Les filtres combinés gardent les listes de résultats utilisables
Une bibliothèque de 10 000 clips n'a pas besoin de vous renvoyer 10 000 résultats. Empilez tags, transcription, visages, type de plan et métadonnées — chaque filtre resserre encore l'ensemble, de sorte que la poignée que vous vouliez vraiment apparaît en quelques secondes.
Quatre modes de récupération, une seule bibliothèque
La recherche par tags utilise un vocabulaire IA énumérable ; la recherche par mots prononcés trouve des mots isolés dans les transcriptions avec Match-All/Match-Any ; la recherche en langage naturel classe les clips à partir d'une description libre, avec les niveaux Relaxed/Balanced/Strict ; la recherche par visage filtre selon les personnes regroupées à partir des visages détectés. Utilisez le mode adapté à la question.
Windows uniquement pour l'instant
ClipCatalog fonctionne sur Windows 10 et 11. L'application choisit le chemin matériel le plus rapide disponible — DirectML, Vulkan ou CPU — mais les versions Mac et Linux ne sont pas prévues à court terme.
À quoi ressemble vraiment l'« échelle des To »
Des ordres de grandeur concrets sur un matériel représentatif (GPU classe Vulkan récente, disque catalogue en NVMe). Vos chiffres bougeront avec le mix de codecs, la taille du modèle et la vitesse du stockage — voyez ceci comme un cadre de planification, pas un SLA strict.
Bibliothèque de test représentative
≈24 To de vidéo source, ≈3 000 heures, répartis sur trois disques internes et un partage NAS. Les chiffres ci-dessous sont un ordre de grandeur destiné à la planification pour une bibliothèque de ce gabarit — vos chiffres réels varieront selon le mix de codecs, le matériel et les étapes IA activées.
Latence du premier résultat
Une requête sur un tag contre l'index complet de 20 000 clips renvoie ses premiers résultats en 2-5 secondes sur la configuration de référence. Chaque couche de filtre supplémentaire coûte une fraction de seconde ; la partie la plus lente reste en général la recherche vectorielle en langage naturel.
Empreinte du catalogue sur disque
Vignettes, tags IA, transcriptions, données de visages et vecteurs sémantiques ajoutent du stockage à votre vidéo source. L'écran Paramètres → Utilisation du stockage répartit le total en direct par catégorie en Mo — mesurez votre empreinte réelle après le premier passage d'indexation plutôt que de partir d'une estimation.
Durée du premier passage d'indexation
Pour les bibliothèques de plusieurs To, prévoyez la première passe en tâche de fond la nuit ou pendant un week-end — le temps d'indexation dépend fortement du mix de codecs, de la classe de GPU et du nombre d'étapes IA activées. Le pipeline supporte les reprises, donc il survit aux redémarrages et aux changements de disques.
Coût d'une synchronisation incrémentale
Après la première passe, seuls les clips nouveaux ou modifiés repassent dans la pipeline IA. L'index existant n'est jamais reconstruit. Une synchro quotidienne sur une bibliothèque active atteint généralement l'état « à jour » en quelques minutes, même si l'archive sous-jacente est à l'échelle des To.
L'économie de la recherche dans une archive de 10 To
Les services de transcription dans le cloud facturent généralement entre 0,005 et 0,024 $ par minute d'audio. Sur une archive de plusieurs To représentant des centaines d'heures de source, ne serait-ce qu'une seule transcription se chiffre déjà en milliers de dollars — avant les frais de palier de stockage, les licences de recherche par utilisateur ou l'egress (l'egress cloud coûte 0,05-0,09 $ par Go, soit 500 à 900 $ de plus si vous voulez un jour récupérer 10 To). La facture grossit avec la bibliothèque ; plus vous y restez, pire le calcul devient.
ClipCatalog traite les fichiers directement sur les disques que vous possédez déjà, indexe localement avec le GPU que vous avez déjà et range tout dans une base SQLite chiffrée sur votre machine. 99 $ unique. Aucune bande passante, aucun egress, aucun abonnement. Une bibliothèque de 50 To et une de 5 To coûtent le même prix en licence ; le coût dominant, c'est le matériel de stockage que vous possédez déjà.
Vous comparez des outils local-first pour de grandes archives ? Consultez le comparatif gestion vidéo orientée vie privée pour voir comment ClipCatalog s'en sort sur l'ingestion à l'échelle des téraoctets, la recherche couvrant toute la bibliothèque et les workflows hors ligne.
Rechercher dans une grande vidéothèque — FAQ
Quelle taille de bibliothèque ClipCatalog peut-il gérer ?
Il est conçu pour des archives de plusieurs téraoctets réparties sur plusieurs dossiers, disques et volumes. Base catalogue, index vectoriel et file d'attente sont prévus pour passer à l'échelle ; sur un PC moderne, la limite pratique est surtout l'espace disque pour les miniatures et embeddings, pas un nombre de vidéos en dur.
Combien de temps prend la première passe d'indexation sur une bibliothèque de plusieurs To ?
Cela dépend fortement du matériel, du mélange de codecs et du nombre d'étapes IA activées. Sur plusieurs téraoctets, il vaut généralement mieux laisser la première passe tourner une nuit ou un week-end sur un PC équipé d'un GPU. L'indexation est entièrement reprenable.
Les requêtes restent-elles rapides à mesure que la bibliothèque grossit ?
Oui — c'est précisément ce que l'architecture vise. Les recherches par tag et transcription utilisent des colonnes indexées du catalogue SQLite local ; les requêtes sémantiques et de visage s'appuient sur un index vectoriel local. Les deux sont conçus pour rester rapides à mesure que la bibliothèque grandit ; pour une même requête, une bibliothèque de 50 000 clips n'est que marginalement plus lente qu'une de 5 000.
Puis-je enregistrer des combinaisons de filtres pour ne pas avoir à les reconstruire ?
Oui — les préréglages de recherche sont une fonctionnalité de premier ordre. Regroupez une recherche par tags, un filtre de mot de transcription, un filtre de visages et une plage de dates dans un préréglage nommé, puis relancez-le en un clic. Les préréglages restent pertinents même quand la bibliothèque évolue.
Puis-je vraiment combiner tags, transcription, visages et métadonnées dans une seule recherche ?
Oui. Les filtres des catégories Visuel, Audio, Métadonnées, Localisation et Technique s'appliquent tous à la même liste de résultats. Chacun retire les correspondances qui ne satisfont pas sa condition, si bien que des filtres empilés ramènent très vite une liste à cinq chiffres à une poignée exploitable.
Les fonctionnalités qui paient le plus à mesure que la bibliothèque grossit
Trois capacités pèsent de façon disproportionnée à l'échelle : les préréglages enregistrés qui transforment des requêtes récurrentes en un seul clic, la classification du type de plan qui sépare dialogue, voix off et scènes avant même que vous appliquiez d'autres filtres, et une barre de recherche unifiée qui empile tags, transcription, visages et métadonnées dans une seule requête.
Recherche vidéo
Préréglages enregistrés et interface de recherche unifiée où tags, transcription, visages et métadonnées se composent en une seule requête — la surface de travail où le filtrage couvrant toute la bibliothèque a réellement lieu.
Contenu détecté
Le vocabulaire de tags auto-généré est conçu pour rester rapide à mesure que la bibliothèque grandit — la recherche par tag sur 100 000 clips devrait se comporter comme sur 10 000.
Recherche dans les transcriptions
Des colonnes indexées dans le catalogue SQLite local maintiennent les recherches d'un mot dans la transcription rapides sur des centaines de milliers de clips. Le Match-All/Match-Any sur plusieurs mots se compose pareil.
Reconnaissance faciale
Les clusters de personnes survivent à la croissance de la bibliothèque : les nouveaux clips de la même personne s'attachent au cluster existant, si bien que retrouver tout ce qui contient un visage récurrent reste une opération en un clic, quelle que soit la taille de la bibliothèque.
Comparaisons pertinentes
Si vous comparez ce flux de travail à d'autres outils, commencez par ces pages comparatives.
Guides connexes centrés sur le problème
Trouver les B-rolls par contenu visuel
Tags visuels générés automatiquement avec combinaisons Match-All / Match-Any — le complément naturel de la recherche combinée à l'échelle de la vidéothèque.
Organiser vos rushes sur disques et NAS
Dès qu'une archive dépasse l'échelle du To, le matériel vit presque toujours sur plusieurs disques et partages NAS. Le guide compagnon pour unifier la couche de stockage.
Rechercher des vidéos par mots prononcés
Recherche d'un mot dans la transcription sur une archive indexée localement par Whisper — le complément « au mot près » de la recherche combinée couvrant toute la bibliothèque.
Trouver une personne dans votre vidéothèque
Recherche par visage à travers dossiers, disques et années de rushes — le pendant « par personne » de la recherche combinée couvrant toute la bibliothèque.
Essayez ClipCatalog gratuitement — jusqu'à 500 vidéos
Aucun compte requis. Vos séquences restent sur votre ordinateur.