테라바이트급 영상 라이브러리를 로컬에서 몇 초 만에 검색하세요.
아카이브가 색인되면 ClipCatalog는 태그 검색, 발화 단어 검색, 자연어 설명 검색, 얼굴 필터, 메타데이터 필터를 라이브러리 전체에 적용되는 하나의 질의 경로로 묶습니다. 몇 번의 클릭만으로 수천 개의 클립을 수십 개로 좁힐 수 있습니다.
분당 요금도, 구독료도 없습니다. 99달러 라이선스 하나로 모든 드라이브에서 모든 영상을 검색할 수 있습니다.
“그 안 어딘가에 있다”라는 문제
용량이 몇 테라바이트를 넘기면, 잘 짠 폴더 구조만으로는 부족해집니다. 그 컷이 있다는 건 알지만, 어떤 드라이브의, 어느 여행 폴더의, 어떤 인터뷰의, 어느 테이크인지 알 수 없습니다. 라이브러리 전체를 아우르는 검색이 없으면 결국 스크롤뿐입니다. ClipCatalog는 질의를 던지면 몇 초 만에 알맞은 클립이 떠오릅니다.
라이브러리 전체 검색이 없으면
- 그 컷이 있는 건 알지만, 어느 드라이브의 어느 연도 폴더인지는 모릅니다
- 클라우드 SaaS 요금은 라이브러리 크기에 비례해 늘어납니다 — 정작 검색이 가장 필요한 순간에
- 단일 목적 도구는 태그·자막·얼굴 중 하나만 색인할 뿐, 셋을 동시에 다루지는 못합니다
ClipCatalog와 함께라면
- 검색창 하나로 모든 폴더·드라이브·연도의 영상을 아우릅니다
- 태그·발화 단어·얼굴·날짜 범위를 하나의 질의로 묶을 수 있습니다
- 저장 프리셋이 자주 쓰는 다중 필터 질의를 한 번의 클릭으로 호출할 수 있게 만들어 줍니다
라이브러리 전체 영상 검색 작동 방식
테라바이트 규모에서는 세 가지 조건이 충족돼야 합니다. 모든 클립에 하나의 검색에서 접근할 수 있어야 하고, 모든 검색 방식이 동일한 색인을 사용해야 하며, 색인은 드라이브 재배치에도 살아남아야 합니다. ClipCatalog는 이 세 가지를 모두 로컬에서 처리합니다.
동영상 검색 →모든 폴더를 가리키기
내장 드라이브, 외장 SSD, NAS 공유, 보관용 디스크를 추가합니다. ClipCatalog는 각각을 저장 볼륨 단위로 추적하므로 드라이브 이동·이름 변경·분리·재연결 주기에도 카탈로그가 유지됩니다. 디렉터리의 일부만 색인하고 싶으면 하위 폴더를 제외할 수 있습니다.
로컬 AI가 색인을 구축
썸네일 추출, AI 시각 태깅, Whisper 자막화, 얼굴 검출, 자연어 검색용 임베딩까지 모두 사용자의 하드웨어에서 실행됩니다. 가능한 경우 DirectML 또는 Vulkan을 사용하고, 그렇지 않으면 CPU로 폴백합니다. 첫 패스는 일회성 비용이고, 이후 모든 검색은 로컬 색인을 향합니다.
필터를 겹쳐 쌓아 검색
태그·전사·얼굴·푸티지 타입·메타데이터 필터를 하나의 질의에 함께 묶습니다. 필터를 더할 때마다 결과가 더 좁아지고, 10 000개짜리 라이브러리는 몇 초 만에 손에 꼽힐 정도로 줄어듭니다. 다시 쓸 조합은 프리셋으로 저장해 두면, 다음 검색은 한 번의 클릭이면 됩니다.
마침내 쉬워지는 라이브러리 전체 검색 예시
라이브러리 전체 검색이 실제로 어떻게 동작하는지 보여 주는 검색 6가지 — 시각 태그 하나에서부터, 네 개 필터를 한꺼번에 묶은 저장 프리셋까지. 모두 색인이 이미 구축되어 있다는 전제이며, 그다음의 질의 자체는 어려운 부분이 아닙니다.
테라바이트급 영상 라이브러리를 누가 검색할까요?
스크롤을 멈추고 질의를 던지는 순간, 라이브러리 전체 검색의 가치가 드러나는 6가지 실제 아카이브 형태입니다.
10년 단위로 색인된 콘텐츠를 가진 방송사 뉴스 아카이브
약 40 TB, 8만 개 클립, 매일 자료를 꺼내 쓰는 뉴스룸 편집실 네 곳. 사건이 터지면 묻는 건 "이 인물·이 장소·이 사건에 대해 우리가 이미 가진 게 뭐지?"입니다. 얼굴 필터 + 자막 단어 검색 + 날짜 범위가 10년치 보도 자료에서 몇 초 만에 답해 줍니다.
수십 년에 걸쳐 권리 처리 완료된 카탈로그를 가진 스톡 푸티지 라이브러리
수십만 개의 클립, 모두 화면에 보이는 것을 기준으로 태깅돼 있습니다. 바이어는 매우 구체적인 브리프를 들고 옵니다("골든아워에 슬로모션으로 찍은 해안선 드론 샷"). Strict 엄격도의 자연어 묘사 검색 + scenic 푸티지 유형 필터 + 드론 필터가, 수십만 개의 클립을 한 번의 질의로 라이선스 가능한 숏리스트까지 좁힙니다.
진술 영상·바디캠 영상을 가로지르는 법률 e-discovery
디스커버리 단계의 25 TB 분량 녹화 자료 — 진술, 바디캠 발췌, 인근 CCTV 덤프. 상대측이 질문을 던지면, 특정 용어가 언급된 모든 클립을 제3자에게 봉인 자료를 업로드하지 않고 빠르게 찾아내야 합니다. 전체에 대해 자막 단어 검색을 돌리고, 날짜 범위와 발화자 얼굴로 좁힙니다.
여러 시즌에 걸친 경기·훈련 영상 라이브러리 위에서의 스포츠 분석
전체 경기 멀티카메라 캡처 5시즌 분량에 매일의 훈련 영상까지 더하면 합쳐서 수십 테라바이트입니다. 분석가는 “우리가 패한 경기들에서, 선수 X가 시작한 모든 역습”을 원합니다. 얼굴 필터 + 해당 액션 태그 검색 + 패배 경기 메타데이터 필터가 수년치 테이프를 한 번의 질의로 집중 분석용 릴로 만들어 줍니다.
10년에 걸친 대학 미디어 랩과 과학 영상 아카이브
실험 기록 80 TB — 행동 실험, 현미경 캡처, 현장 촬영, 타임랩스 장치. 다음 논문에는 과거 연구와 비교 가능한 영상이 필요합니다. Balanced 엄격도의 자연어 묘사 검색 + 날짜 범위 필터는 10년치 자료에서 비교 가능한 실험 회차를 전부 끄집어내, 대학원생이 외장 드라이브를 2주 동안 뒤지지 않아도 되게 합니다.
완료된 클라이언트 작업을 보관하는 포스트프로덕션 아카이브 볼트
계약상 보관 기간에 따라 보관 중인 완료 프로젝트 8년치 — 합치면 100 TB를 훌쩍 넘깁니다. 프로듀서가 다시 와서 “2024년 봄 코스메틱 캠페인의 라이프스타일 릴”을 요청하면, 클라이언트 태그 + 프로젝트 날짜 범위 + 대사 없는 푸티지 유형을 묶은 저장 프리셋이, 아카이브 대부분이 콜드 드라이브에 있어도 몇 초 만에 정확한 릴을 돌려줍니다.
테라바이트 규모에서 기대할 수 있는 것
큰 라이브러리는 색인 파이프라인의 모든 단계에 부담을 줍니다. ClipCatalog는 테라바이트 규모에서 실제로 중요한 트레이드오프를 중심으로 만들어졌습니다 — 여기 솔직한 이야기를 정리해 두었습니다.
첫 색인이 가장 큰 비용
수 TB 규모의 라이브러리라면 첫 패스를 하룻밤이나 주말에 돌릴 계획을 잡으세요. 완료된 후의 증분 동기화는 새로 추가된 자료만 처리합니다. 필요할 때 멈췄다 이어서 진행해도 됩니다 — 진행 상황은 유지됩니다.
하드웨어 설정으로 속도는 사용자 손에
콘텐츠 분석용 GPU, Whisper 자막화용 GPU, 얼굴 검출용 장치를 각각 따로 선택할 수 있습니다. 내장 벤치마크를 돌리면 ClipCatalog가 사용 중인 PC에 가장 빠른 구성을 제안합니다.
10만 개를 넘겨도 응답 시간은 실용적인 수준 유지
색인은 빠른 조회용으로 튜닝된 로컬 벡터 DB와 암호화된 SQLite 카탈로그 위에 구축됩니다. 2만 개짜리 라이브러리에서 단일 태그나 단어 질의는 수 초 안에 첫 결과를 돌려주고, 라이브러리가 두 배가 돼도 응답성은 유지됩니다.
복합 필터가 결과 목록을 다룰 만한 크기로 유지
1만 개의 클립이 있는 라이브러리라고 결과가 1만 개여야 할 이유는 없습니다. 태그·자막·얼굴·푸티지 유형·메타데이터 필터를 함께 쌓아 보세요 — 필터를 더할수록 집합이 더 좁아져서, 정말 원하던 한 줌이 몇 초 안에 떠오릅니다.
네 가지 검색 방식, 하나의 라이브러리
태그 검색은 AI가 만든 열거 가능한 어휘를 사용하고, 발화 단어 검색은 자막 속 단어를 Match-All/Match-Any로 찾으며, 자연어 검색은 자유 묘사에 대해 Relaxed/Balanced/Strict 엄격도로 클립의 순위를 매기고, 얼굴 검색은 감지된 얼굴에서 군집화된 인물 기준으로 필터링합니다. 질문에 맞는 모드를 골라 쓰세요.
현재는 Windows 전용
ClipCatalog는 Windows 10과 11에서 동작합니다. 가능한 가장 빠른 하드웨어 경로(DirectML, Vulkan, CPU)를 자동으로 선택하지만, Mac과 Linux 빌드는 가까운 로드맵에 없습니다.
“테라바이트 규모”가 실제로 어떤 모습인지
대표적인 하드웨어 환경(비교적 최신의 Vulkan급 GPU, 카탈로그용 NVMe 디스크)에서의 자릿수 단위 수치입니다. 코덱 구성, 모델 크기, 저장 장치 속도에 따라 값이 달라지므로 — 계획을 잡는 틀로 보시고, 확정된 SLA로 보지는 마세요.
대표적인 테스트 라이브러리
원본 영상 ≈24 TB, ≈3,000시간 분량을 내장 드라이브 3개와 NAS 공유 1개에 분산해 둔 환경입니다. 아래 수치는 이런 라이브러리에 대한 자릿수 수준의 계획용 모델이며, 실제 수치는 코덱 구성, 하드웨어, 활성화된 AI 단계에 따라 달라집니다.
첫 결과까지의 지연 시간
2만 개짜리 전체 색인에 대한 단일 태그 질의는 레퍼런스 장비에서 2-5초 안에 첫 결과를 돌려줍니다. 필터를 한 단계 더 쌓을 때마다 1초 미만이 추가되며, 가장 느린 부분은 보통 자연어 벡터 조회입니다.
카탈로그가 차지하는 디스크 용량
썸네일, AI 태그, 전사, 얼굴 데이터, 시맨틱 벡터는 모두 원본 영상 위에 저장소를 더 차지합니다. 설정 → 저장소 사용량 화면은 현재 합계를 카테고리별 MB로 보여 주므로, 추정치 대신 첫 인덱싱 후의 실제 사용량을 기준으로 계획하세요.
첫 색인 패스 소요 시간
수 TB 규모의 라이브러리는 첫 번째 패스를 야간 또는 주말 백그라운드 작업으로 계획하세요 — 인덱싱 시간은 코덱 구성, GPU 등급, 활성화한 AI 단계 수에 크게 좌우됩니다. 파이프라인은 재개가 가능해서 재부팅과 드라이브 교체도 견딥니다.
증분 동기화 비용
첫 패스가 끝난 뒤에는 새로 추가되거나 변경된 클립만 AI 파이프라인을 거칩니다. 기존 색인은 절대 재구축되지 않습니다. 작업 중인 라이브러리의 일일 동기화는 보통 몇 분 안에 “따라잡힘” 상태가 되며, 아래 깔린 아카이브가 TB 규모여도 마찬가지입니다.
10 TB 아카이브를 검색한다는 일의 경제학
클라우드 전사(transcription) 서비스는 보통 오디오 1분당 $0.005-$0.024 사이를 청구합니다. 수 TB 아카이브는 원본으로 수백 시간 분량이라, 한 번 자막화하는 것만으로도 청구액이 네 자릿수 달러까지 올라갑니다 — 스토리지 티어 요금, 사용자당 검색 좌석, egress 비용(클라우드 egress는 GB당 $0.05-$0.09, 10 TB를 다시 받아오려면 추가로 $500-$900) 이전에. 청구서는 라이브러리와 함께 커지고, 오래 머무를수록 계산은 더 나빠집니다.
ClipCatalog는 사용자가 이미 가진 드라이브에서 자료를 읽고, 이미 가진 GPU로 로컬에서 색인을 만들며, 모든 것을 사용자 PC의 암호화된 SQLite 데이터베이스에 저장합니다. 99 달러 일회 결제. 대역폭도, egress도, 정기 구독도 없습니다. 50 TB짜리 라이브러리와 5 TB짜리 라이브러리의 라이선스 비용은 동일하며, 지배적인 비용은 이미 보유한 스토리지 하드웨어입니다.
큰 아카이브를 위한 로컬 우선 도구들을 비교 중이신가요? 프라이버시 우선 영상 관리 라운드업에서 테라바이트 규모 인제스트·라이브러리 전체 검색·오프라인 워크플로 측면에서 ClipCatalog의 위치를 확인할 수 있습니다.
큰 영상 라이브러리 검색 — FAQ
ClipCatalog는 얼마나 큰 라이브러리를 처리할 수 있나요?
여러 폴더·드라이브·볼륨에 흩어진 수 TB 규모의 아카이브를 전제로 설계되었습니다. 카탈로그 DB, 벡터 색인, 작업 큐 모두 확장 가능하며, 현대적인 PC에서의 실질적인 상한은 영상 개수가 아니라 썸네일과 임베딩을 위한 저장 공간입니다.
테라바이트 규모 라이브러리의 첫 색인은 얼마나 걸리나요?
하드웨어, 코덱 구성, 활성화한 AI 단계 수에 따라 크게 달라집니다. 수 TB짜리 라이브러리에서는 GPU가 달린 PC에서 첫 패스를 하룻밤이나 주말 동안 돌리는 편이 보통 유리합니다. 색인 작업은 완전히 이어서 진행할 수 있습니다.
라이브러리가 커져도 검색 속도는 유지되나요?
네 — 그 부분이 바로 아키텍처가 노린 핵심입니다. 태그·자막 검색은 로컬 SQLite 카탈로그의 인덱스 컬럼을 사용하고, 의미·얼굴 검색은 로컬 벡터 색인을 사용합니다. 둘 다 라이브러리가 커져도 빠르게 유지되도록 설계되어 있으므로, 같은 형태의 질의라면 5천 개 라이브러리와 5만 개 라이브러리의 속도 차이는 미미합니다.
필터 조합을 매번 다시 만들지 않도록 저장해 둘 수 있나요?
네 — 검색 프리셋 저장은 정식 기능입니다. 태그 검색·자막 단어 필터·얼굴 필터·날짜 범위를 하나의 이름 있는 프리셋으로 묶고, 다음에는 한 번의 클릭으로 다시 실행할 수 있습니다. 라이브러리가 시간이 지나며 커져도 프리셋은 합리적으로 유지됩니다.
정말 한 번의 검색에서 태그·자막·얼굴·메타데이터 필터를 모두 묶을 수 있나요?
네. Visual·Audio·Metadata·Location·Technical 카테고리의 필터가 모두 동일한 결과 목록에 적용됩니다. 각 필터가 자신의 조건에 맞지 않는 매치를 잘라내므로, 필터를 겹치는 것만으로 5자리 결과 목록을 다룰 만한 분량으로 빠르게 줄일 수 있습니다.
라이브러리가 커질수록 가치가 커지는 기능
규모가 커질수록 효과가 비대칭적으로 커지는 기능이 세 가지 있습니다. 반복되는 질의를 한 번의 클릭으로 바꿔 주는 저장 프리셋, 다른 필터를 적용하기 전부터 대사·내레이션·풍경 컷을 분류해 두는 푸티지 유형 분류, 그리고 태그·자막·얼굴·메타데이터를 하나의 쿼리에 쌓는 통합 검색 바입니다.
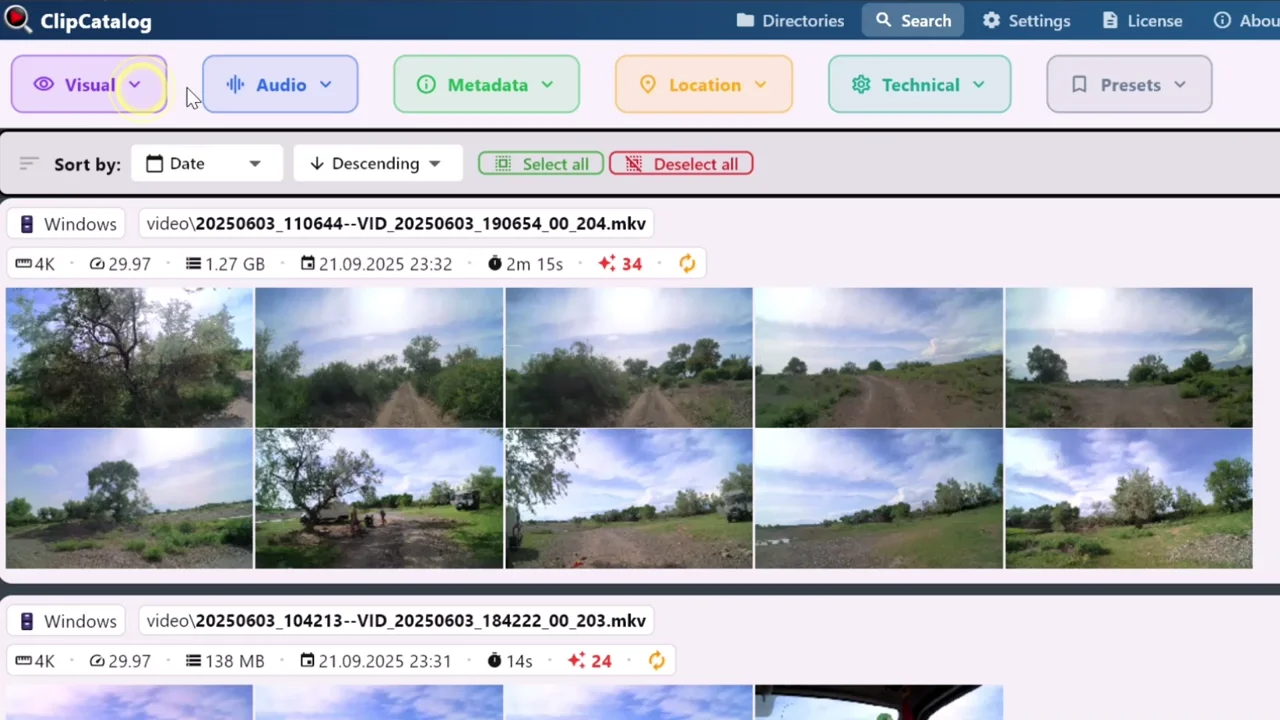
동영상 검색
저장 프리셋과, 태그·자막·얼굴·메타데이터 필터가 하나의 쿼리로 합쳐지는 통합 검색 인터페이스 — 라이브러리 전체에 대한 필터링이 실제로 일어나는 작업 공간입니다.
탐지된 콘텐츠
자동 생성된 태그 어휘는 라이브러리가 커져도 빠르게 유지되도록 설계돼 있어, 10만 개짜리 라이브러리에서의 태그 검색 경험은 1만 개일 때와 비슷할 것입니다.
대본 검색
로컬 SQLite 카탈로그의 인덱스 컬럼 덕분에, 수십만 개의 클립을 가로지르는 단일 단어 자막 검색도 빠른 속도가 유지됩니다. 다중 단어에 대한 Match-All/Match-Any도 같은 방식으로 조립됩니다.
얼굴 인식
인물 클러스터는 라이브러리가 커져도 유지됩니다. 같은 사람의 새 클립은 기존 클러스터에 붙으므로, 라이브러리가 아무리 커져도 자주 등장하는 얼굴을 가진 모든 클립을 찾는 일은 한 번의 클릭으로 끝납니다.
관련 비교
이 워크플로를 다른 도구와 비교하고 있다면, 먼저 이 나란한 비교 페이지부터 확인하세요.
관련 문제 중심 가이드
화면에 보이는 것으로 B-roll 찾기
자동 생성된 시각 태그에 Match-All / Match-Any 조합까지 — 라이브러리 전체를 아우르는 복합 검색을 자연스럽게 보완합니다.
드라이브와 NAS에 흩어진 영상 정리
아카이브가 TB 규모로 들어서면 영상은 거의 항상 여러 드라이브와 NAS 공유에 분산됩니다. 저장 계층을 하나로 묶기 위한 동반 가이드입니다.
발화 단어로 영상 검색
Whisper로 로컬에서 색인된 아카이브에 대한 단어 단위 자막 검색 — 라이브러리 전체 통합 검색을 단어 단위로 보완합니다.
라이브러리 안에서 특정 인물 찾기
폴더·드라이브·여러 해치 영상에 걸친 얼굴 검색 — 라이브러리 전체 통합 검색을 “인물 단위”로 짝지어 줍니다.
ClipCatalog 무료 체험 — 최대 500 개의 동영상
계정 등록이 필요 없습니다. 촬영한 영상은 컴퓨터에 그대로 보관됩니다.